
2020 最流行的十个 Python 库

大家好,本文是一个英文博客的简单翻译。
https://tryolabs.com/ 博客网站每年都会评选最流行的 Python 库,而 2020 年已经是第六届了(虽然现在已经是 2021 年的尾声了,但是 2020 年的推荐也很值得看一下,我们也期待 2021 年的推荐)。
评选规则非常的简单,这些 Python 库都符合如下条件:
1、在 2020 年发起或者流行(大规模使用)
2、他们被很好的维护
3、他们很优秀,值得你们去了解
声明:2020 年,我们选择的 Python 库很多是机器学习和数据科学相关的,虽然他们确实对非数据科学相关的人员也很有用。此外,除了我们选择的主要 10 个库,另外还增加了一个致敬的荣誉表彰章节,这些是我们认为也值得给大家推荐的。
这篇博文的重点是给出我们对这些库的一些洞见,同时希望能够引发你们的一些思考,同时也可以给我们一些补充,以免我们错误了一些其他的优秀 Python 库。
好了,那就来看一下我们推荐的 10 个 Python 库吧。
1. Typer

亲自编写命令行程序是一个很耗费时间的事情,你不应该每次都这样做。而 Typer 就是这样一款跟 FastAPI、tiangolo 有相同设计理念的工具,通过借助 Python 3.6+ 的类型提示功能,我们能够更好的定义命令行的接口。
这样的设计让 Typer 更为出众。使用 Typer 除了让你的代码更好的被文档化,同时对于命令行程序的参数验证也变得非常的容易。同时依赖类型提示功能,你可以很容易的做到代码的自动补全,这样会极大的提升效率。
为了更好的提升 Typer 的能力,Typer 内部使用了被广泛使用的 Click 项目,这样 Typer 就可以借助 Click 的优势,比如社区、插件等,简单快速的完成命令行程序的开发工作。
一如既往,Typer 跟其他被推荐的项目一样,有非常友好的文档,Typer 非常值得推荐。
2. Rich
接着刚才的命令行程序的主题,有人说终端的命令行程序只能是黑白绿的单色系,真的吗?
你是不是想增加更多的颜色和风格?能够打印复杂的表格?轻松的展示漂亮的进度栏?展示 Markdown?表情包?Rich 项目都能够实现。我们来看一下下面的截图来看一下是否都能够实现。
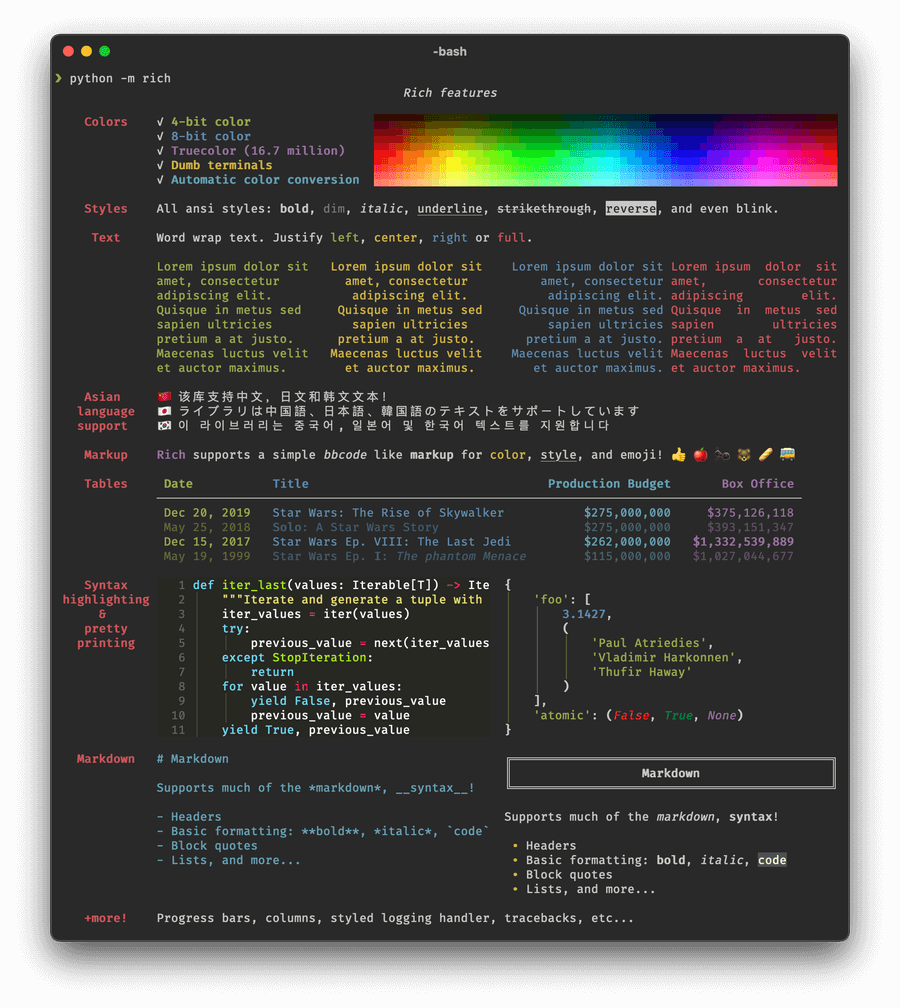
Rich 项目绝对是一款能够让命令行程序体验上升一个档次的工具。
3. Dear PyGui
我们都知道,命令行程序也可以很美观,但是还是不得不说,体验上还是有不太友好的地方,所以对于命令行程序来说需要一个真正的 GUI。
今天要介绍的开源项目 DearPyGui,使用的是在视频游戏中常见的技术,也就是即时渲染模式。这就意味着动态的 GUI 每一帧都是独立渲染的,我们不需要去持久化数据,这个特性使得 DearPyGui 与其他的 Python GUI 框架完全不同。DearPyGui 性能非常的好,它可以使用电脑的 GPU 来高速渲染界面,这在工程化、仿真、游戏、数据科学应用上非常的有用。
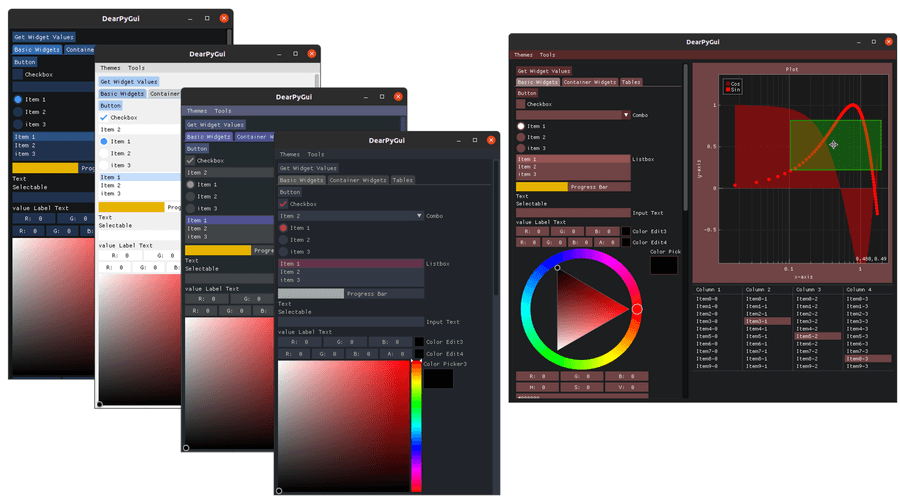
而 DearPyGui 另外一个优势就是,它非常容易学习很容易上手,在 Windows 10 、Linux、MacOS 上都可以使用。
4. PrettyErrors
The joy of simplicity. This is one of the libraries that make you think: how is it that nobody thought about this before?
PrettyErrors does only one thing and does it well. In terminals that support colored output, it transforms the cryptic stack traces into something that is much better suited for parsing with our puny human eyes. No more scanning the entire screen to find the culprit of your exception… You can now find it at a glance!

5. Diagrams
We programmers like to solve problems and code. But sometimes, we need to explain intricate architectural designs to other colleagues as part of the very much needed project documentation. Traditionally, we have resorted to GUI tools where we can work on diagrams and visualizations to put in presentations and documents. But it’s not the only way.
Diagrams lets you draw the cloud system architecture without any design tools, directly in Python code. It has icons that will come in handy for several cloud providers, including AWS, Azure, GCP. It makes it dreadfully easy to create arrows and groups. Really, it’s only a few lines of code!

The best thing of code-based diagrams? You get the ability to track changes with version control via your standard git! Developers will be happy.
6. Hydra and OmegaConf
When doing research and experimentation on machine learning projects, there’s always a myriad of settings to try out. In non-trivial applications, configuration management can become rather complicated, pretty fast. Wouldn’t it be nice to have a structured way of dealing with this complexity?
Hydra is a tool that allows you to build configurations in a composable manner, and override certain parts from the command line or config files.
To illustrate some of the common tasks that can be simplified with the library, let’s say there’s a base architecture of a model we’re experimenting on, and multiple variations of it. With Hydra, a base configuration can be defined, and then multiple jobs be run with variations of them:
python train_model.py variation=option_a,option_b
├── variation
│ ├── option_a.yaml
│ └── option_b.yaml
├── base.yaml
└── train_model.py
Hydra’s cousin, OmegaConf, provides a consistent API for the base of the hierarchical configuration system, supporting different sources like YAML, config files, objects and CLI arguments.
A must for doing configuration management in the 21st century!
7. PyTorch Lightning
Every tool that increases the productivity of a data science team is worth gold. There is no reason to make people that work in data science projects re-invent the wheel every time, think over and over again how to better organize the code in their project, use some “PyTorch boilerplate” that is not very well maintained, or trade potential control for using a higher level abstraction.
Lightning helps boost productivity by decoupling the science from the engineering. It is sort of like Keras for TensorFlow, in the sense that it makes your code a lot more concise. However, it does not take your control away. It’s still PyTorch, and you have access to all the usual APIs.
This library helps teams leverage software engineering’s good practices around organization and clear responsibilities of components, to build high quality code that can easily scale to train on multiple GPUs, TPUs and CPUs.

A library that will help those junior members of the data science team produce better results, but also, more experienced members will love it because of the increase in overall productivity, without giving up control.
8. Hummingbird

Not all machine learning is deep learning. Very often, your models consist of more traditional algorithms implemented in scikit-learn (such as Random Forest), or you use gradient boosting methods like popular LightGBM and XGBoost.
However, a lot of advancements are happening in the deep learning field. Frameworks like PyTorch are advancing at a breathtaking pace, and hardware devices are being optimized to run tensor computations faster and with lower power consumption. Wouldn’t it be nice if we could leverage all this work, to run our traditional methods faster and more efficiently?
Here is where Hummingbird comes in. This new library by Microsoft can compile your trained traditional ML models into tensor computations. This is great, because it frees you of the need to re-engineer your models.
As of now, Hummingbird supports conversion to PyTorch, TorchScript, ONNX, and TVM, and a variety of ML models and vectorizers. The inference API is also very similar to the Sklearn paradigm, which lets you reuse your existing code but changing your implementation to what’s generated by Hummingbird. This is a tool to keep an eye on, as it gains support for mode models and formats!
9. HiPlot
Nearly every data scientist has worked with high dimensional data at some point during their career. Unfortunately, human brains are not adequately wired for dealing with this kind of data intuitively, so we must resort to other techniques.
Early this year, Facebook released HiPlot, a library that helps discover correlations and patterns in high-dimensional data using parallel plots and other graphical ways to represent information. The concept is explained in their launch blog post, but it’s basically a nice and convenient way of visualizing and filtering high dimensional data.

HiPlot is interactive, extensible, and you can use it from your standard Jupyter Notebooks or via it’s own server.
10. Scalene
As the ecosystem of Python libraries grows increasingly more complex, we find ourselves writing more and more code that depends on C extensions and multi-threaded code. This becomes a problem when it comes to measuring performance because the profilers built into CPython don’t handle multi-threaded and native code properly.
That’s when Scalene comes to the rescue. Scalene is a CPU and memory profiler for Python scripts capable of correctly handling multi-threaded code and distinguishing between time spent running Python vs. native code. There’s no need to modify your code, you just need to run your script from the command line with scalene and it will generate a text or HTML report for you, showing CPU and memory usage for each line of your code.

Bonus: Norfair
We couldn’t finish this list without including our own homegrown baby for video analytics applications.
Norfair is a customizable lightweight Python library for real-time object tracking. In other words, it assigns a unique id to every detected object in different frames, letting you identify them as they move through time. Using Norfair, you can add tracking capabilities to any detector with just a few lines of code. “Any detector”? Yes. No matter what the object representation looks like: a bounding box (4 coordinates), a single point centroid, the output of a human pose estimation system with a variable number of key points above a certain probability threshold, or anything else.

The function used to calculate the distance between tracked objects and detections is defined by the user, making it fully customizable if you need it.
It’s also fast and it can run real-time. However, the real beauty is that it is very modular, and you can take your existing detection codebase and add tracking capabilities to it, with only a few lines of code. We are welcoming any comments and suggestions, and work on improving the capabilities of Norfair every day!
Honorable mentions
- quart — an async web framework with Flask-compatible API. Some of the existing Flask extensions will even work!
- alibi-detect — monitor outliers and distribution drift in your production models, for tabular data, text, images and time series.
- einops — popularized in 2020, einops lets you write tensor operations for readable and reliable code, supporting numpy, PyTorch, TensorFlow, and others. Recommended by Karpathy, do you need anything else?
- stanza — accurate natural language processing tools on 60+ languages, from Stanford. Multiple available pre-trained models for different tasks.
- datasets — from HuggingFace, lightweight and extensible library to easily share and access datasets and evaluation metrics for Natural Language Processing (NLP) and more
- pytorch-forecasting — eases timeseries forecasting with neural networks for real-world cases and research alike.
- sktime — provides dedicated time series algorithms and scikit-learn compatible tools for building, tuning, and evaluating composite models. Also check their companion sktime-dl package for deep learning based models.
- netron — a visualizer for neural network, deep learning and machine learning models. Supports more formats than I even knew existed.
- pycaret — wraps several common ML libraries and makes you vastly more productive, saving you hundreds of lines of code.
- tensor-sensor — helps you get the dimensions of your tensor math right, by improving error messages and providing visualizations.
I want to thank Ian Tayler, Germán Hoffman and Sebastián Sosa for the collaboration on this blog post.




LIKE WHAT YOU READ?
Subscribe to our newsletter and get updates on Deep Learning, NLP, Computer Vision & Python.
No spam, ever. We’ll never share your email address and you can opt out at any time.
What to read next
-
Top 10 Python libraries of 2019
-
Top 10 Python libraries of 2018
-
Getting started with AWS: open source workshop
Get in touch
Tell us a bit about your project, we’d love to see how we can help. You can send us an email or just fill out the form below.
![]()
更多详情请查看如下链接:https://tryolabs.com/blog/2020/12/21/top-10-python-libraries-of-2020/
更多精彩请扫码关注如下公众号。