
是时候考虑大模型如何真正在企业落地了,一款企业级 LLMOps 开源了!

大家好,又见面了,我是 GitHub 精选君!
基于大模型进行应用开发的开源项目有许多,以下是常见的几个:
-
以 Langchain 可视化为特色的 flowise、Langflow …
-
以提示词工程和知识库问答为特色的 Dify、FastGPT …
-
以多智能体为特色的 ChatDev、AutoGen …
但当我们试图将这些项目用于企业实际场景落地时,往往发现缺东少西,总无法完美契合需求。
今天给大家推荐一个新兴 GitHub 开源项目:BISHENG 一款主打企业级落地的大模型应用开发平台。

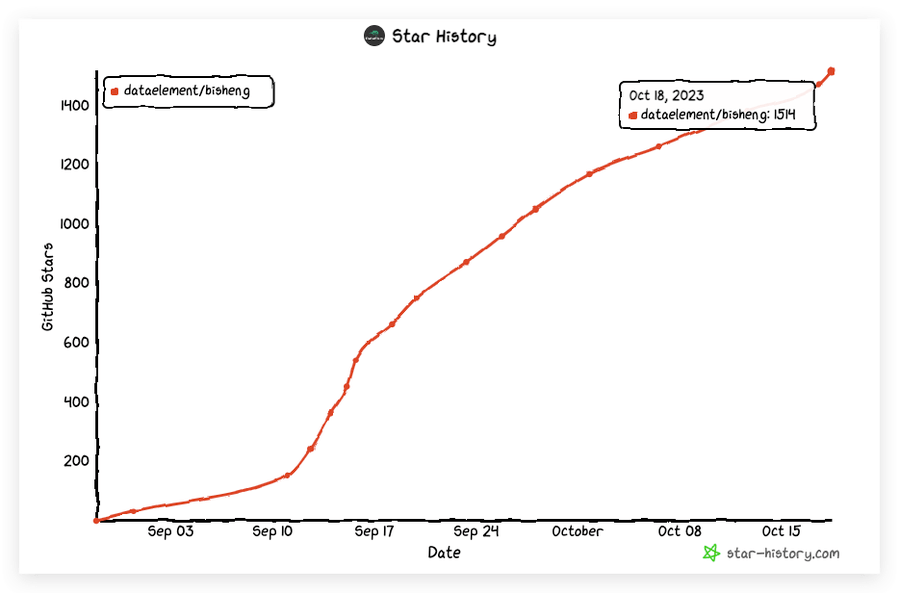
该项目自 9 月初开源以来,一个月已获得1.5K Star。License 也非常友好,基于 Apache 2.0 License 开源,允许二开商用。
BISHENG 平台围绕企业级大模型应用的落地提供了许多特色能力。
落地应用针对性优化
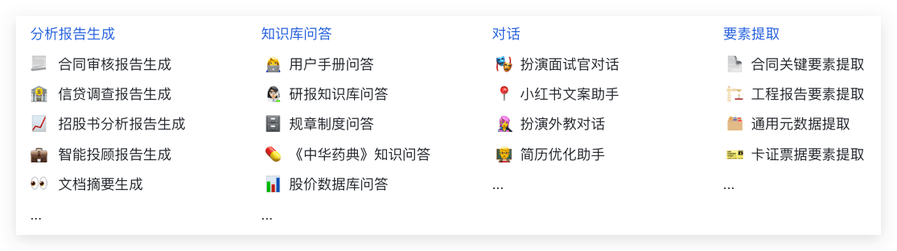
BISHENG 除了支持基础的提示词工程与知识库问答能力,还支持各类分析报告生成、文档要素提取、文档摘要标签生成等实用能力,这些均可通过可视化编排的方式实现。
Roadmap 中提到,未来还将新增 [流程自动化]、[语音对话] 等新的应用形态。
针对如 [知识库问答] 这样的头部场景,其实仅使用向量搜索在许多场景中都会出现漏召回的问题,BISHENG 中提供了MixEsVectorRetriever 组件,融合向量与 ES 关键词的召回结果,在各类场景的综合评测中,实现了 10~20% 的效果提升。
免费的高精度文档解析能力
企业内的数据往往是比较“脏”的,比如各种 PDF 扫描件、图片文件、PPT、Excel、Word 等,这些数据如何进入知识库,涉及到比较繁杂的数据预处理工作。
BISHENG 直接提供了免费且据称效果业内顶尖的文档解析能力,包括高精度 OCR 文字识别(含手写体)、表格识别(含无边框表格)、版式分析、印章识别能力。
基于高质量文档解析结果,在进行文档切分并存入大模型知识库时,会基于这些版式信息进行切分,保障语义连续与完整,进而极大提升知识库问答效果(如果直接基于简单的字数策略进行切分,许多关键信息都会被切断,比如整个表格一分为二)。
同时,基于以上信息,BISHENG 平台还实现了答案参考来源在源文件中实现精准定位的功能。实现了回答的可信、可控。

灵活的可视化编排
在 BISHENG 平台中,可通过可视化的方式灵活构建应用能力。
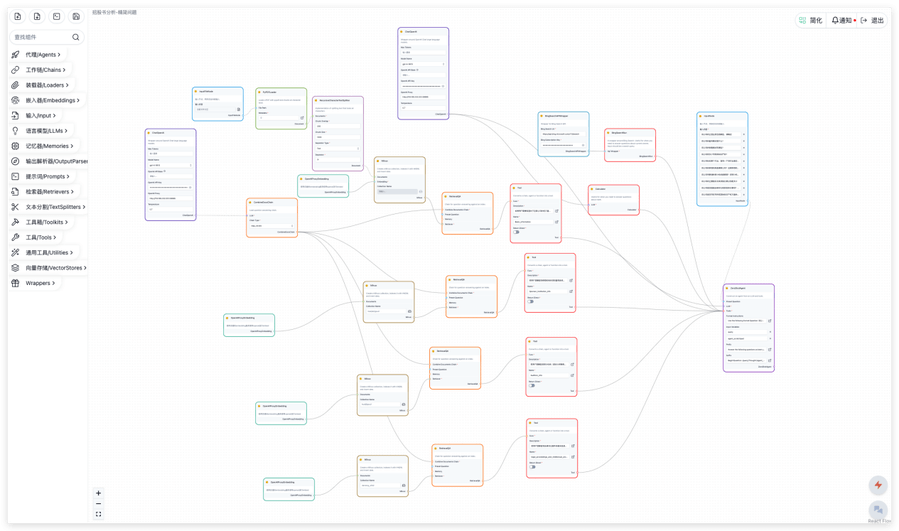
这个部分 BISHENG 基于知名开源项目 Langflow 进行了封装优化,完整适配整个 Langchain 快速发展的生态。
同时,BISHENG 在 Langchain 已有的几百个组件能力基础上,结合企业落地实际需求新增了许多自研组件,如提升知识库召回效果的 MixEsVectorRetriever 组件,如自动触发报告分析的 PresetQuestion 组件等。
项目 Roadmap 中提到,未来还将引入 “类AutoGen” 这样的多智能体组件,进一步提升复杂问题处理效果。
“收编”所有大模型
除了 Langchain 已适配的国外大模型,BISHENG 还对国内所有主流大模型(文心一言、讯飞星火、智谱、MInimax…)进行了适配。
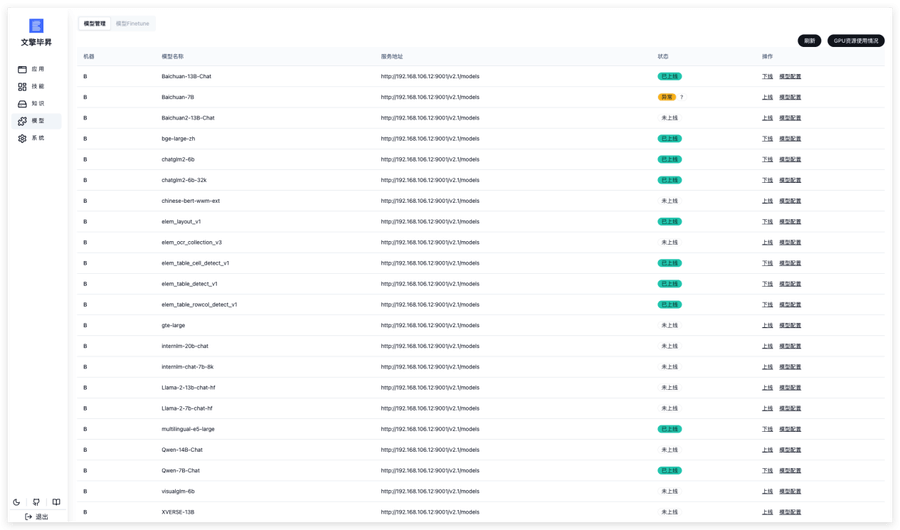
不仅如此,BISHENG 平台还支持管理本地私有化部署的对话大模型及 embedding 模型服务,结合算力管理,可以实现灵活便捷的大模型上下线操作。同样,所有主流开源私有化模型接口均完成了适配。
以上模型能力在官方 demo 环境中可以直接体验测试。
此外,BISHENG 目前已完成银河麒麟操作系统、华为鲲鹏 CPU+ 华为昇腾加速卡、海光 CPU+ 寒武纪加速卡适配。未来还将适配更多国产生态。
BISHENG 提供了非常全面的在线文档支持,并且从开发者微信群中观察到,团队对于开源社群的支持非常及时,基本群里的每个问题都会被团队成员回复。
更多项目详情请查看如下链接。
开源项目地址:https://github.com/dataelement/bisheng
项目在线文档:https://dataelem.feishu.cn/wiki/ZxW6wZyAJicX4WkG0NqcWsbynde
更多精彩请扫码关注如下公众号。