
privateGPT - 无数据泄露安全的使用 GPT 与私有文档交互

大家好,又见面了,我是 GitHub 精选君!
背景介绍
在处理敏感文档时,我们常常担心数据的安全性和隐私泄露的风险。privateGPT 正是为了解决这个问题而诞生的。它提供了一种在不连接互联网的情况下与文档进行交互的方式,确保用户的数据完全私密。
privateGPT 的设计旨在全面考虑细节和核心痛点。它提供了一个安全的执行环境,让用户可以在不担心数据泄露的情况下与文档进行交互。
privateGPT 在 GitHub 有超过 29.2k Star,用一句话介绍该项目就是:“Interact privately with your documents using the power of GPT, 100% privately, no data leaks”。

项目介绍
privateGPT 是一个使用 GPT 的强大功能来与文档进行私密交互的项目。它完全保护用户隐私,没有数据泄露的风险。privateGPT 通过结合 LangChain、GPT4All、LlamaCpp、Chroma 和 SentenceTransformers 构建而成。
这个项目解决了与敏感文档交互时的安全性和隐私保护的问题。它提供了一个执行环境,让用户能够使用 GPT 的功能向文档提问,获取所需的信息,而无需连接互联网。
主要功能特点:
- 提供私密的文档交互功能,无需担心数据泄露
- 支持多种文档格式,包括 CSV、Word 文档、EverNote、Email、EPub、HTML 文件、Markdown、Outlook Message、Open Document Text、PDF、PowerPoint 文档和纯文本文件
- 可自定义选择不同的 GPT4All-J 兼容模型
- 集成了 SentenceTransformers,提供更好的语义理解和查询效果
如何使用
首先,按照以下步骤设置运行环境:
- 安装所有依赖项:
pip3 install -r requirements.txt -
下载 LLM 模型,并将其放置在任意目录下:
- 默认使用 ggml-gpt4all-j-v1.3-groovy.bin 作为 LLM 模型。如果你想使用其他 GPT4All-J 兼容模型,只需下载该模型,并在
.env文件中引用它。
- 默认使用 ggml-gpt4all-j-v1.3-groovy.bin 作为 LLM 模型。如果你想使用其他 GPT4All-J 兼容模型,只需下载该模型,并在
-
将
example.env重命名为.env,并根据需要编辑其中的变量:MODEL_TYPE: supports LlamaCpp or GPT4All PERSIST_DIRECTORY: is the folder you want your vectorstore in MODEL_PATH: Path to your GPT4All or LlamaCpp supported LLM MODEL_N_CTX: Maximum token limit for the LLM model MODEL_N_BATCH: Number of tokens in the prompt that are fed into the model at a time. Optimal value differs a lot depending on the model (8 works well for GPT4All, and 1024 is better for LlamaCpp) EMBEDDINGS_MODEL_NAME: SentenceTransformers embeddings model name (see https://www.sbert.net/docs/pretrained_models.html) TARGET_SOURCE_CHUNKS: The amount of chunks (sources) that will be used to answer a question
然后只需将你需要使用的私有文档放在 source_documents 文件件下。

运行命令 python ingest.py 将会把私有的文档进行向量化,在需要与 GPT 交互时提前进行向量化的匹配。
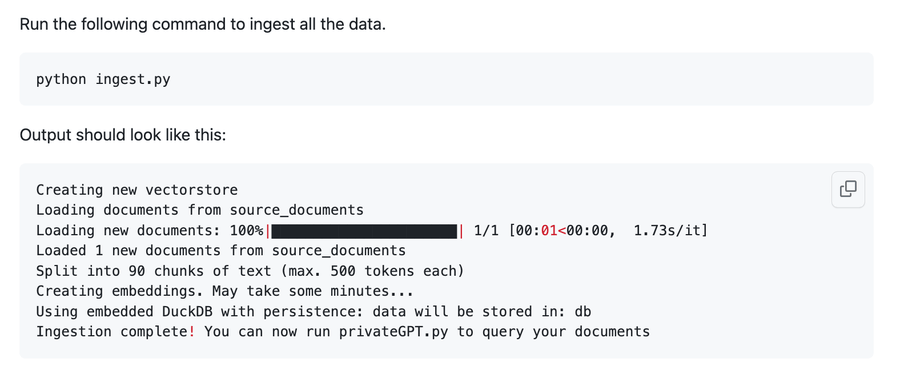
执行完成之后,运行 python privateGPT.py 即可与上述私有文档进行聊天对话,问任何你想知道的问题。
以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/imartinez/privateGPT
开源项目作者:imartinez
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。