
milvus - 下一代 AI 应用存储系统,云原生向量数据库

大家好,又见面了,我是 GitHub 精选君!
背景介绍
ChatGPT 再一次引爆人工智能,而对于人工智能处理的非结构数据来说,能够将非结构的数据进行向量化的存储,有利于后续的 AI 算法的使用。
用专业一点术语就是,在处理嵌入式相似性搜索和人工智能应用时,我们常常遇到一些问题。首先,对于非结构化数据的搜索并不容易,而且在不同的部署环境下使用体验也不一致。其次,存储和计算之间的耦合限制了系统的弹性和灵活性。针对这些问题,我们推荐一个解决方案:Milvus。
Milvus 项目在 GitHub 有超过 20.6k Star,用一句话介绍该项目就是:“A cloud-native vector database, storage for next generation AI applications”。
项目介绍
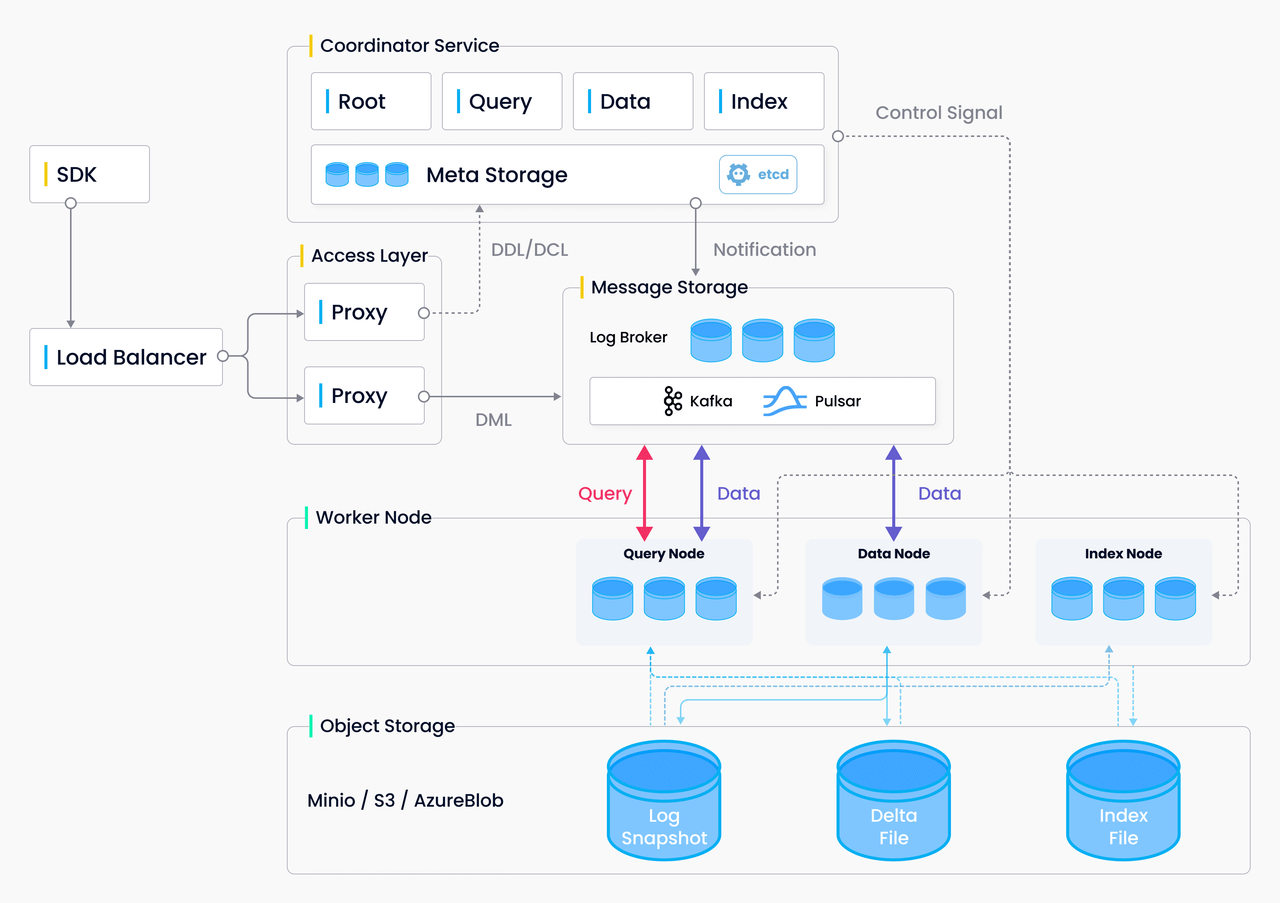
Milvus 是一个面向下一代人工智能应用的云原生向量数据库和存储系统。它通过提供快速的嵌入式相似性搜索功能,使非结构化数据搜索更加便捷。Milvus 2.0 版本采用了存储和计算分离的设计,所有组件都是无状态的,以增强弹性和灵活性。详细的架构细节请参考 Milvus 架构概述(https://milvus.io/docs/architecture_overview.md)。Milvus于2019年10月以开源Apache许可证2.0发布,并且目前是LF AI & Data Foundation的毕业项目。
Milvus 的主要特点包括:
- 兆向量数据集的毫秒级搜索:在兆向量数据集上平均延迟仅为毫秒级。
- 简化的非结构化数据管理:针对数据科学工作流程设计了丰富的API,无论是在笔记本电脑、本地集群还是云端,都提供一致的用户体验。可以将实时搜索和分析集成到几乎任何应用中。
- 可靠的全时段向量数据库:Milvus内置了复制和故障切换/切换回功能,确保数据和应用在发生中断时能够保持业务连续性。
- 高度可扩展和弹性:组件级的可扩展性使得根据需求进行动态扩缩容成为可能。Milvus可以根据负载类型进行组件级的自动扩缩容,提高资源调度效率。
- 混合搜索:除了向量数据,Milvus还支持布尔值、整数、浮点数等数据类型。Milvus的集合可以包含多个字段,以适应不同的数据特征或属性。Milvus将标量过滤与强大的向量相似性搜索相结合,为分析非结构化数据提供现代化、灵活的平台。
以下是 Milvus 的一些使用案例。
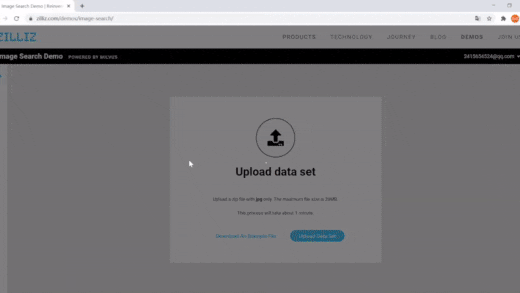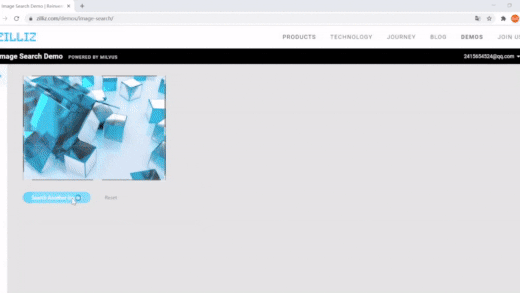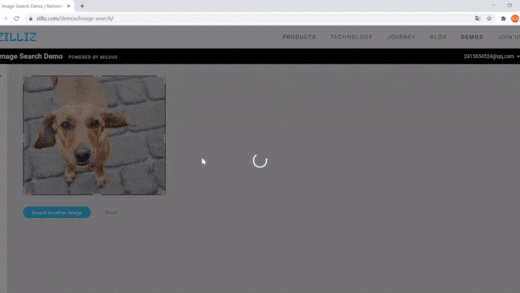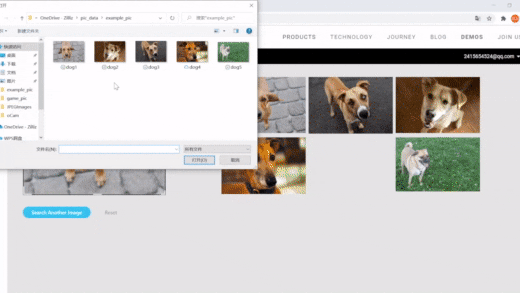
1、图片搜素
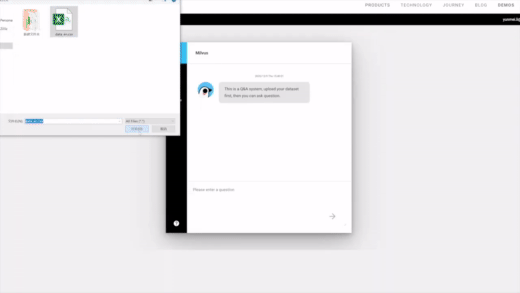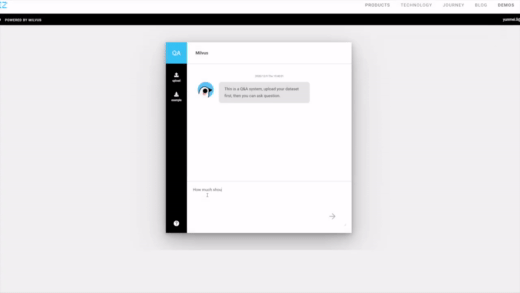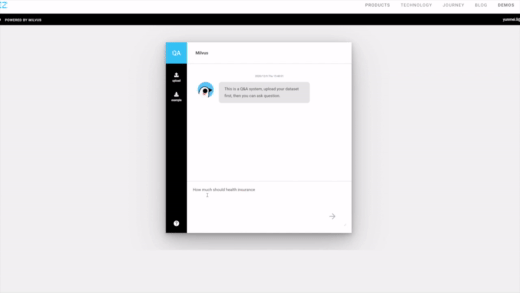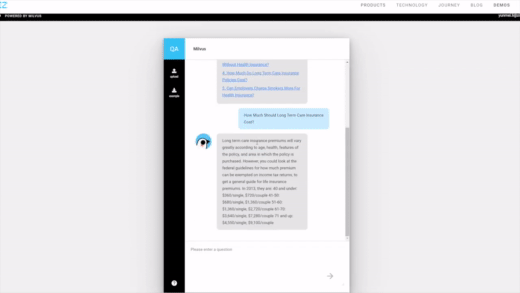
2、聊天机器人
3、化学结构搜索
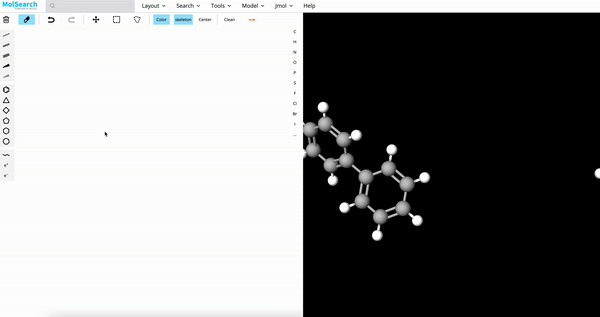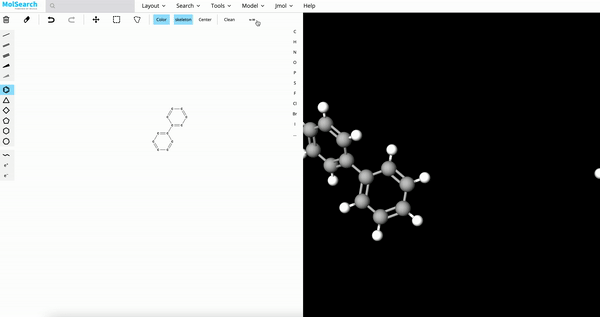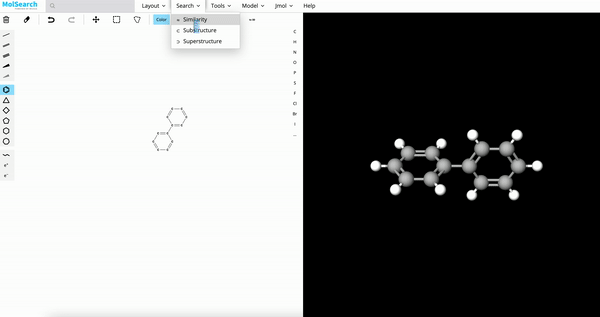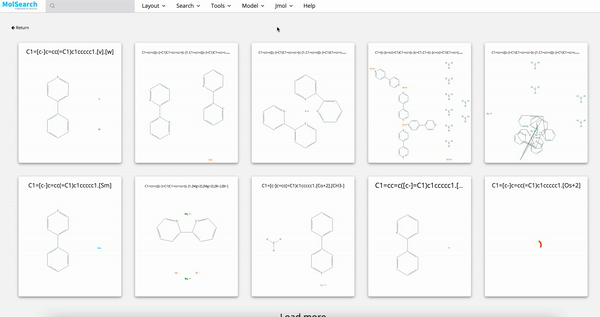
如何使用
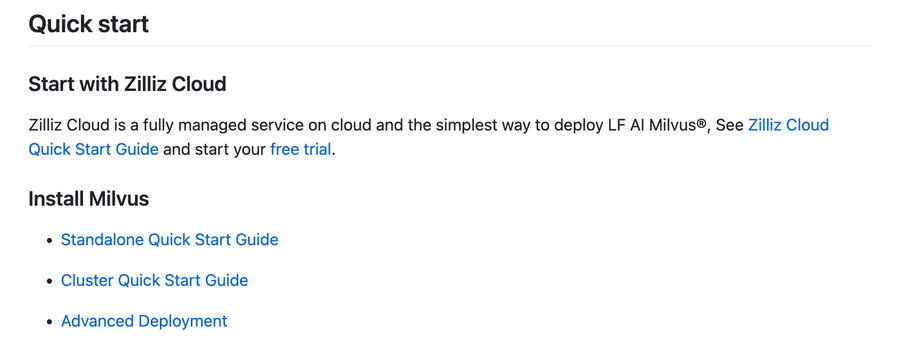
目前使用可以选择云服务或者自主安装的方式。
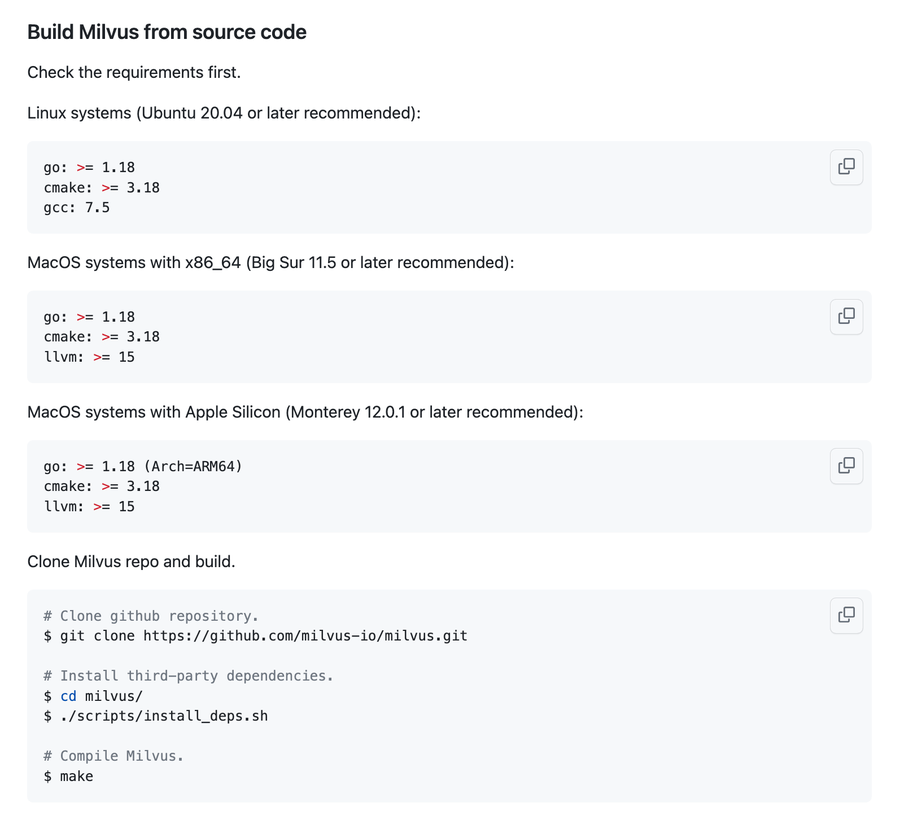
自己安装的话可以从 GitHub 克隆代码进行编译,需要 Go 和 GCC 环境。
安装好后,可以直接使用官方提供的 SDK 进行使用。以下是目前支持的 SDK,支撑语言很全。

以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/milvus-io/milvus
开源项目作者:milvus-io
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。