
机器学习模型测试框架推荐

大家好,又见面了,我是 GitHub 精选君!
背景介绍
在机器学习领域,对于模型的测试是一项关键任务。由于机器学习模型依赖于数据,测试场景会受到特定领域问题的影响,往往是无限多的。那么从哪里开始测试?该实施哪些测试?应该覆盖哪些问题?如何实施这些测试?在Giskard项目中,我们相信机器学习需要自己的测试框架。Giskard 是一个专注于机器学习模型的开源测试框架,涵盖了从表格模型到语言模型(LLMs)的测试需求。
Giskard-AI/giskard 项目在 GitHub 有超过 1000 Star,用一句话介绍该项目就是:“The testing framework dedicated to ML models, from tabular to LLMs”。
![]()
项目介绍
Giskard致力于扫描AI模型以检测偏差、性能问题和错误的风险。它是一个适用于机器学习模型的测试框架,可以从表格模型到语言模型进行测试。Giskard的主要功能包括:
- 扫描模型以发现漏洞:Giskard的扫描功能可以自动检测性能偏差、数据泄漏、不稳定性、虚假相关性、过度自信、不足自信、伦理问题等漏洞。
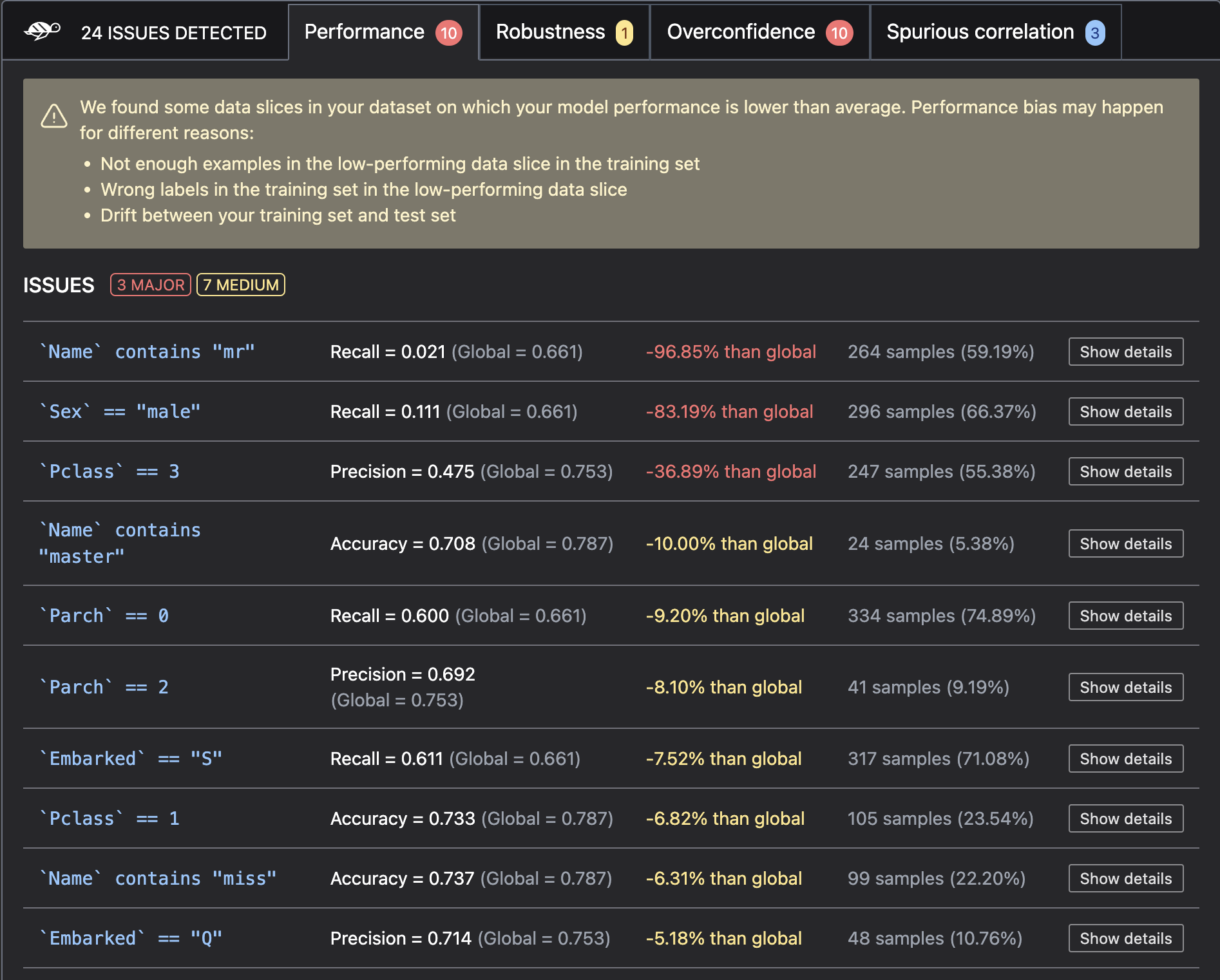
- 自动生成特定领域的测试用例:根据扫描结果,Giskard可以自动生成相关的测试用例。你可以通过定义领域特定的数据切片器和转换器来定制测试用例,以适应你的使用场景。
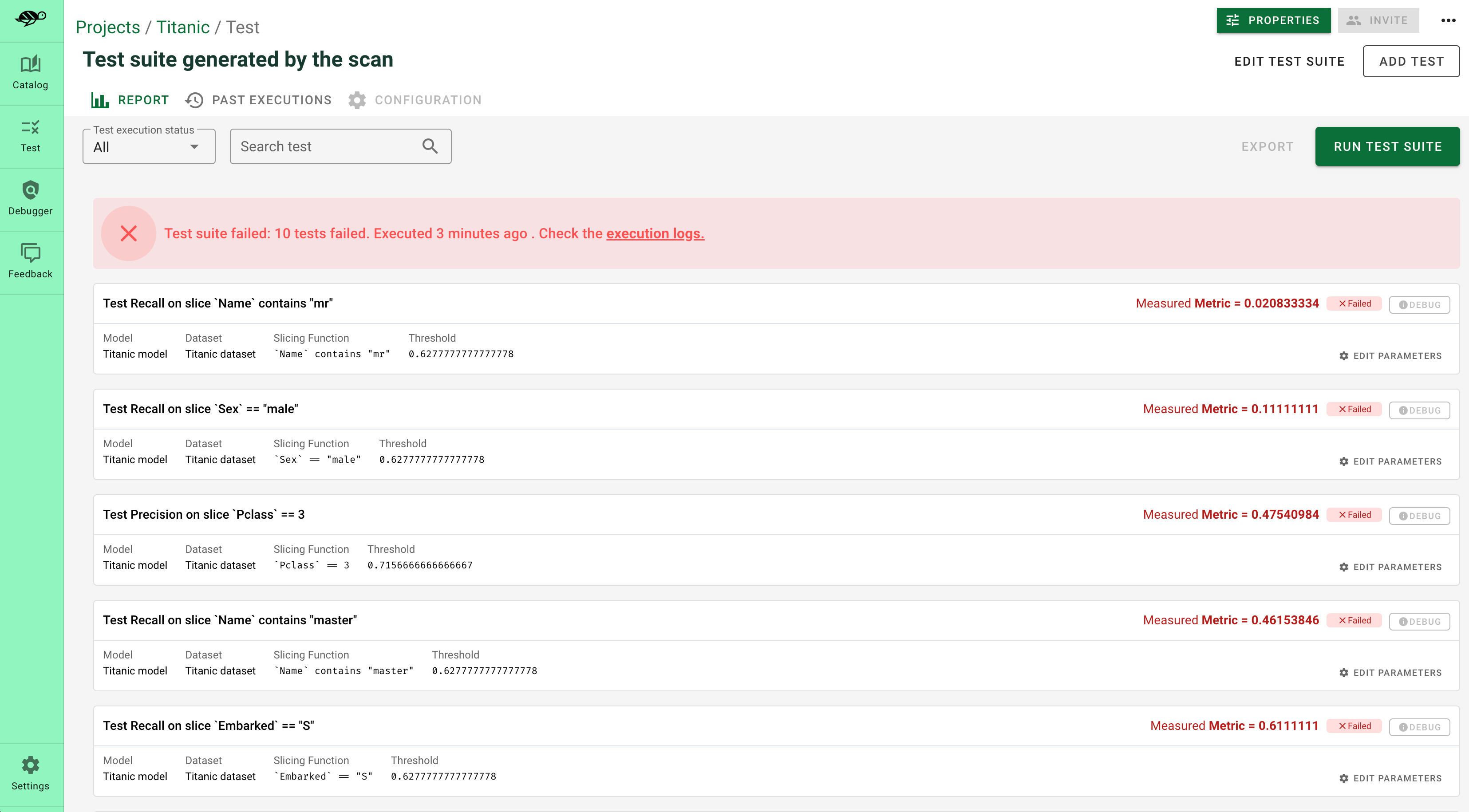
- 借鉴开源社区的质量保证最佳实践:Giskard的目标是成为机器学习质量保证的开源中心,你可以轻松贡献和加载数据切片、转换函数以及AI基础检测器、生成器或评估器。受到Hugging Face哲学的启发,Giskard旨在成为机器学习质量保证的开源平台。
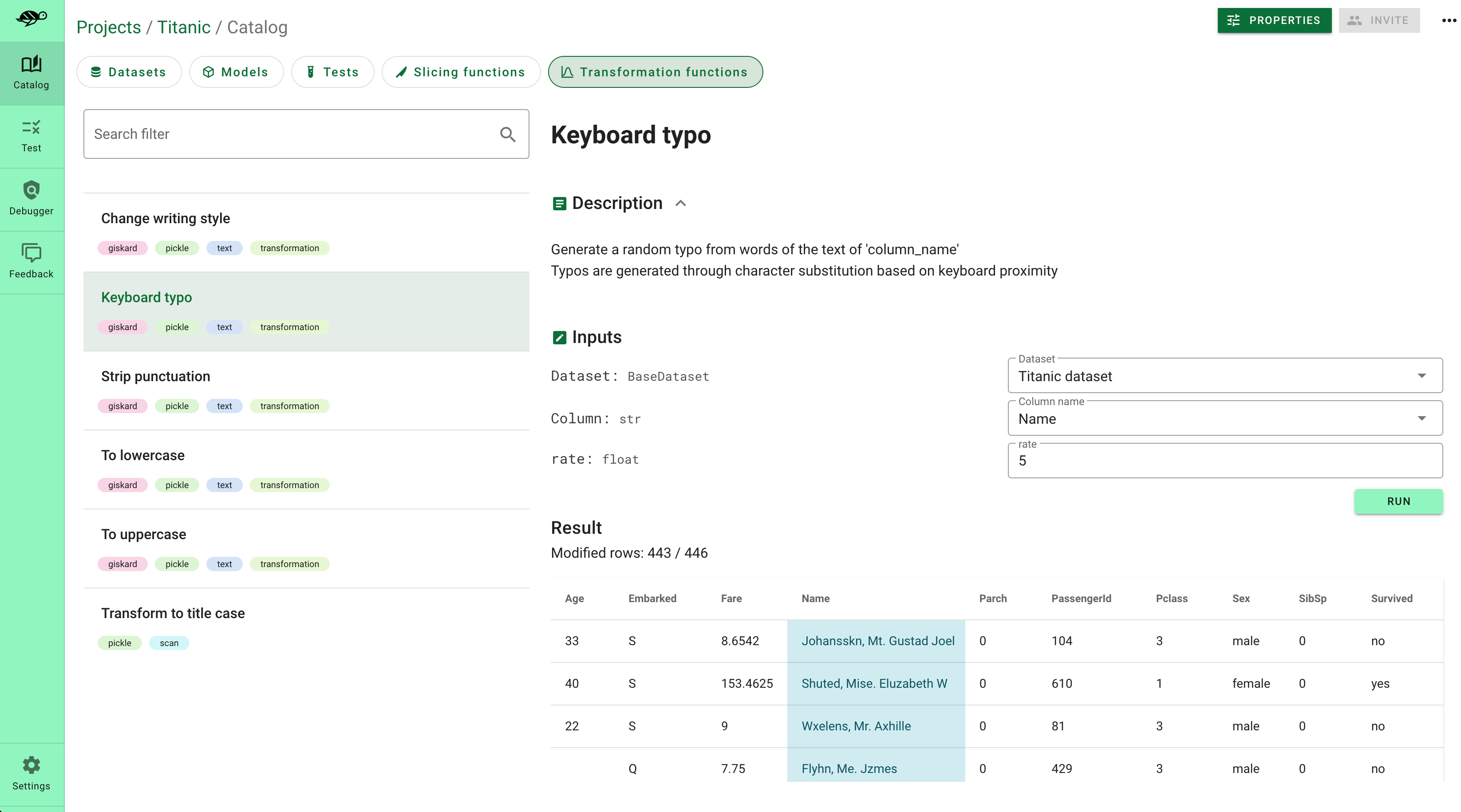
此外,Giskard可以与任何模型和环境配合使用,并与你喜欢的工具无缝集成。

如何使用
- 安装:可以通过以下命令安装Giskard:
pip install "giskard[server]>=2.0.0b" -U giskard server start - 扫描模型以检测漏洞:在封装好模型和数据集之后,你可以使用以下代码对模型进行漏洞扫描:
```python
import giskard
替换这里的模型和数据集
df = giskard.demo.titanic_df() data_preprocessor, clf = giskard.demo.titanic_pipeline()
Wrap your Pandas DataFrame with Giskard.Dataset, containing examples such as:
your test set, a golden dataset, etc.
See https://docs.giskard.ai/en/latest/guides/wrap_dataset/index.html
giskard_dataset = giskard.Dataset( df=df, # A pandas.DataFrame that contains the raw data (before all the pre-processing steps) and the actual ground truth variable (target). target=”Survived”, # Ground truth variable name=”Titanic dataset”, # Optional cat_columns=[‘Pclass’, ‘Sex’, “SibSp”, “Parch”, “Embarked”] # Optional, but is a MUST if available. Inferred automatically if not. )
Wrap your model with Giskard.Model:
you can use any tabular, text or LLM models (PyTorch, HuggingFace, LangChain, etc.),
for classification, regression & text generation.
See https://docs.giskard.ai/en/latest/guides/wrap_model/index.html
def prediction_function(df): # The pre-processor can be a pipeline of one-hot encoding, imputer, scaler, etc. preprocessed_df = data_preprocessor(df) return clf.predict_proba(preprocessed_df)
giskard_model = giskard.Model( model=prediction_function, # A prediction function that encapsulates all the data pre-processing steps and that could be executed with the dataset used by the scan. model_type=”classification”, # Either regression, classification or text_generation. name=”Titanic model”, # Optional classification_labels=clf.classes_, # Their order MUST be identical to the prediction_function’s output order feature_names=[‘PassengerId’, ‘Pclass’, ‘Name’, ‘Sex’, ‘Age’, ‘SibSp’, ‘Parch’, ‘Fare’, ‘Embarked’], # Default: all columns of your dataset # classification_threshold=0.5, # Default: 0.5 )
Then apply the scan
results = giskard.scan(giskard_model, giskard_dataset) ``` 更多的安装和使用细节可以参考项目的文档。
以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/Giskard-AI/giskard
开源项目作者:Giskard-AI
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。