
一个基于 OpenFlamingo 的多模态模型

大家好,又见面了,我是 GitHub 精选君!
背景介绍
在我们日常生活中,存在许多需要指令跟随和上下文学习的场景。然而,传统的模型往往难以同时处理多模态输入和进行准确的指令理解。这导致了问题的难解性和效果的不佳。为了解决这些问题,项目 Otter 应运而生。
Otter 是一个基于 OpenFlamingo(DeepMind 的 Flamingo 开源版本)的多模态模型,它在 MIMIC-IT 数据集上进行训练,展示了改进的指令跟随和上下文学习能力。

项目介绍
Otter 是一个基于多模态指令调整的模型,它通过整合图像和视频输入,实现了更好的上下文学习和指令理解能力。该模型建立在 Flamingo 架构的基础上,并在 MIMIC-IT 数据集上进行了训练。Otter 不仅可以处理多个图像输入作为上下文示例,还支持视频输入。通过在真实场景中进行训练,Otter 可以在各种日常生活情境中进行场景理解、差异识别和视觉助理等任务。
主要功能介绍
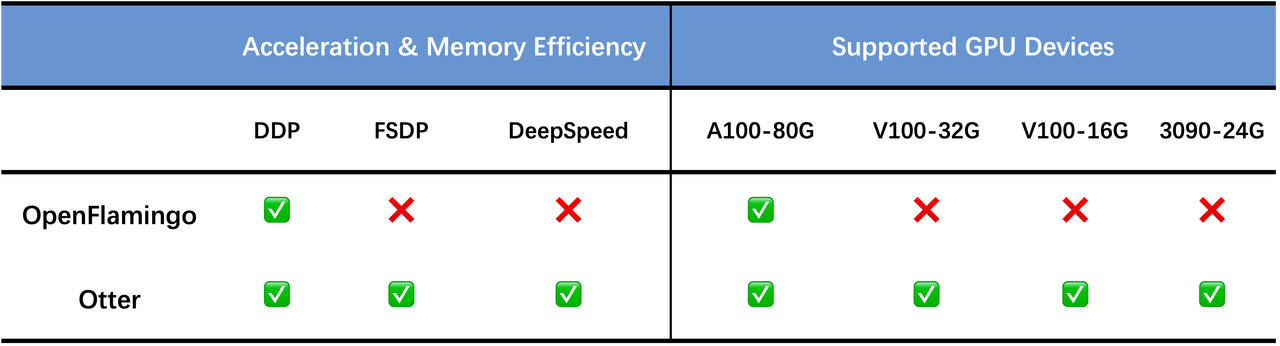
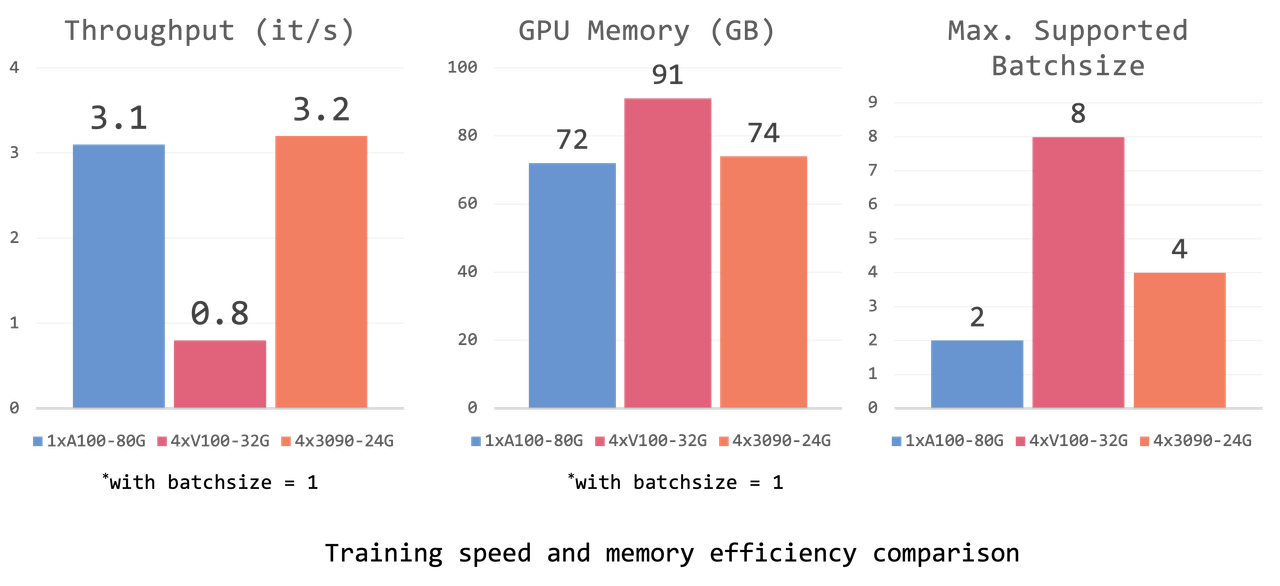
- 支持多模态输入:Otter 是第一个支持以多个图像输入作为上下文示例的多模态指令调整模型。
- 视频输入支持:Otter v0.2 还支持视频输入,视频帧按照原始 Flamingo 实现的方式进行排列。
- 强大的上下文学习能力:通过对真实场景进行训练,Otter 具备了理解日常生活情境、推理上下文、识别观察中的差异和作为视觉助理的能力。
![]()

如何使用
你可以通过以下步骤安装和使用 Otter 项目:
- 下载项目源代码并解压缩。
- 安装所需的依赖项和环境。
- 运行示例代码以了解如何使用 Otter 进行指令跟随和上下文学习。
示例代码:
# 导入 Otter 模块
import otter
# 创建 Otter 实例
otter_model = otter.OtterModel()
# 加载模型权重
otter_model.load_weights('model_weights.pth')
# 输入指令和上下文示例
instruction = '在图像中找到红色的汽车。'
context_images = ['image1.jpg', 'image2.jpg', 'image3.jpg']
# 进行指令跟随和上下文学习
result = otter_model.follow_instruction(instruction, context_images)
# 输出结果
print(result)

以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/Luodian/Otter
开源项目作者:Luodian
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。
Written on June 15, 2023