

大家好,又见面了,我是 GitHub 精选君!
背景介绍
今天要给大家推荐一个 GitHub 开源项目 deepseek-ai/DeepSeek-Coder,该项目在 GitHub 有超过 10.6k Star。
一句话介绍该项目:DeepSeek Coder: Let the Code Write Itself
![]()



项目介绍
深入浅出:DeepSeek Coder - 让代码自我编写
背景介绍:
在软件开发的世界中,快速准确地编写代码是每个开发者的追求,但随着项目复杂性的提升,开发速度往往会受到影响。面临的挑战包括但不限于代码错误、效率低下、维护难度大等问题。特别是对于大型项目,开发者需要消耗大量时间和精力去理解整个项目的结构和逻辑,才能有效地进行代码编写和修改。这不仅减缓了开发进度,还可能导致代码质量下降。此外,在多语言编程环境下的兼容性和语法问题更是让开发者头疼不已。
**

项目介绍:**
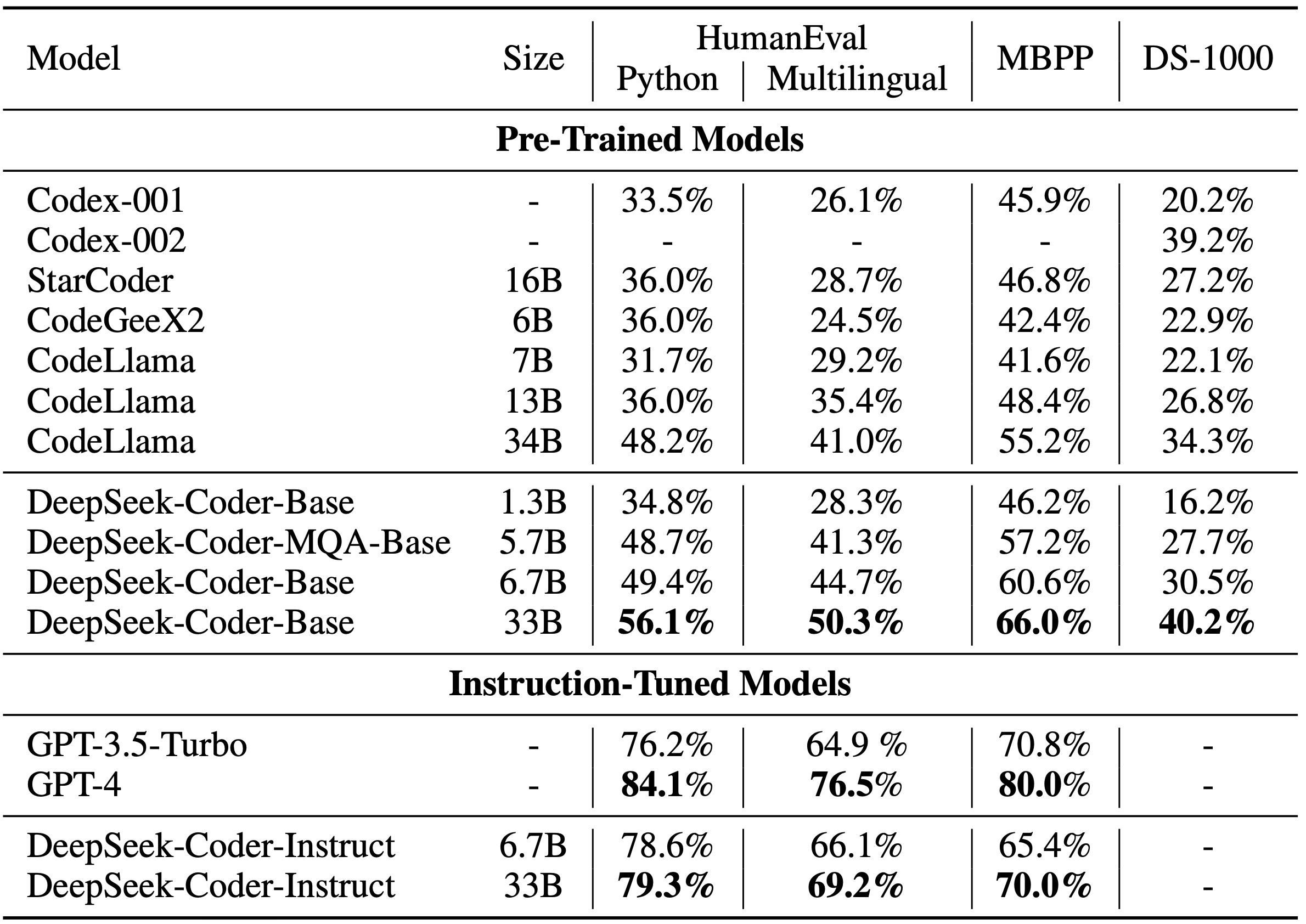
为了解决上述问题, DeepSeek Coder 应运而生。它是一款强大的代码语言模型,通过在 2T tokens 上的从头训练,其中包含 87% 的代码和 13% 的自然语言(包括英文和中文),达到了开源代码模型中的最先进性能。DeepSeek Coder 支持广泛的编程语言,包括 Python、Java、C++ 等多达数十种语言,能够在多种编程环境下提供优秀的代码补全和代码插入能力。模型大小从 1B 到 33B 不等,用户可以根据自己的需求选择合适的模型大小。DeepSeek Coder 不仅能够支持项目级别的代码补全和代码插入,还能在多个编程语言和各种基准测试中提供最先进的性能。
如何使用:
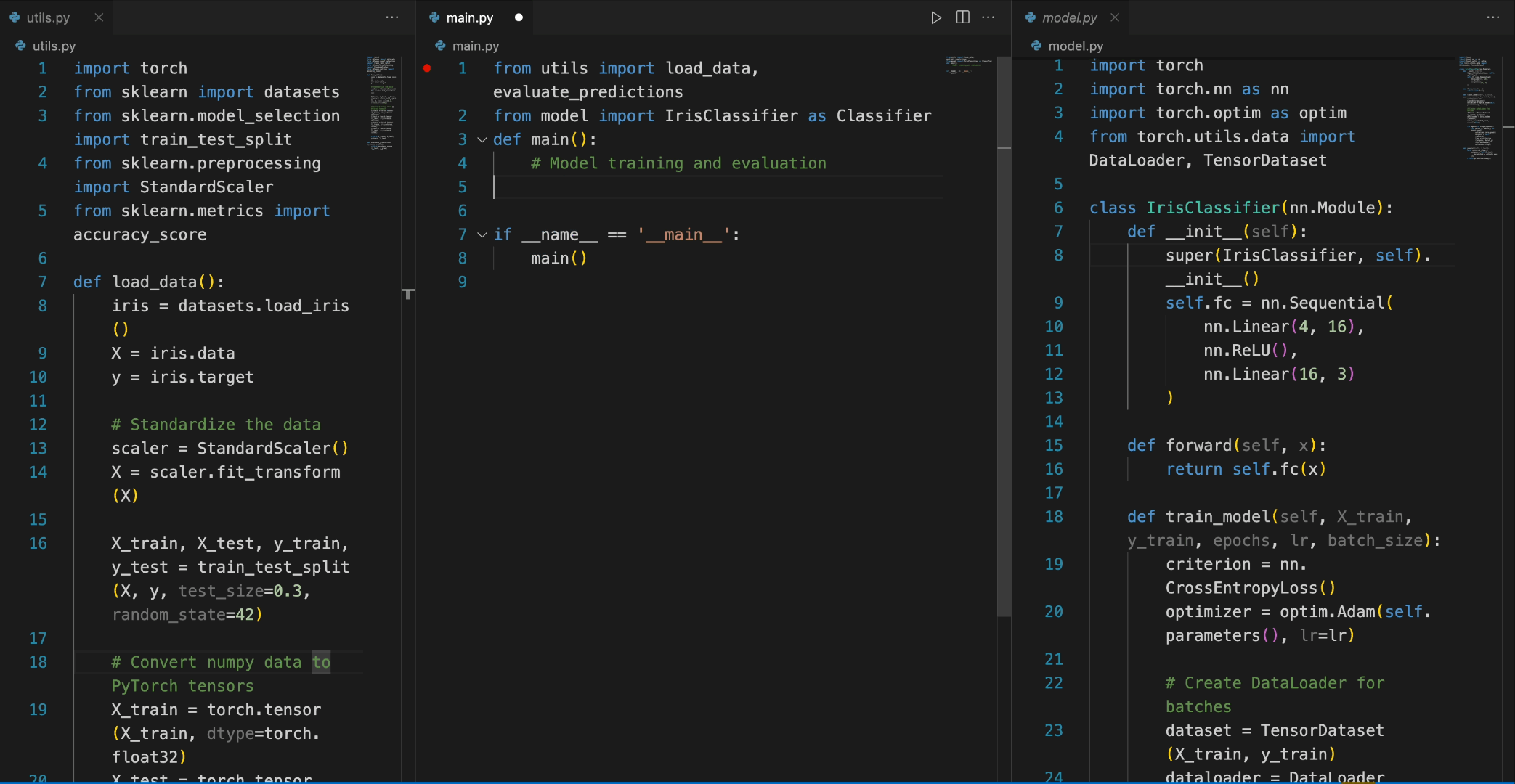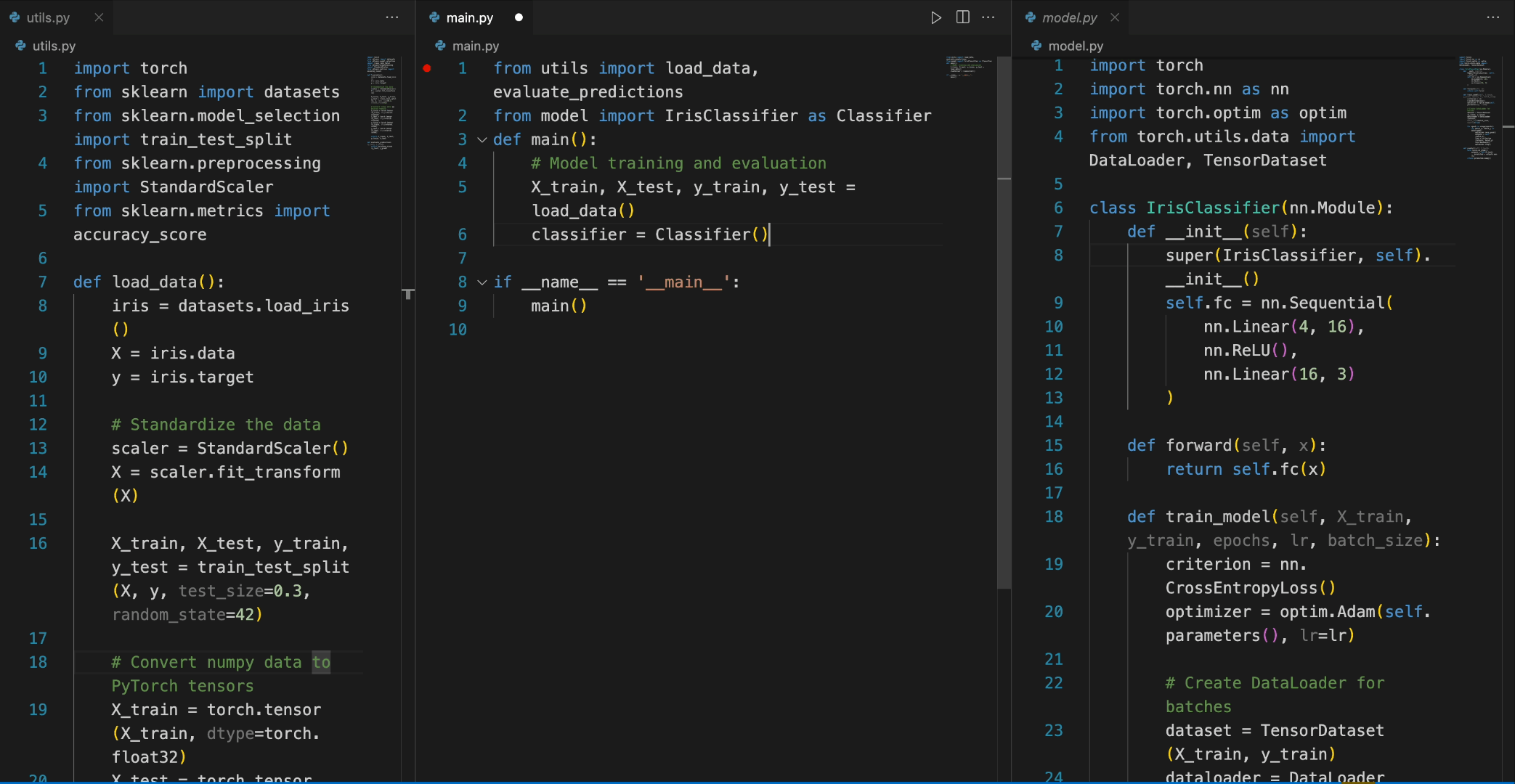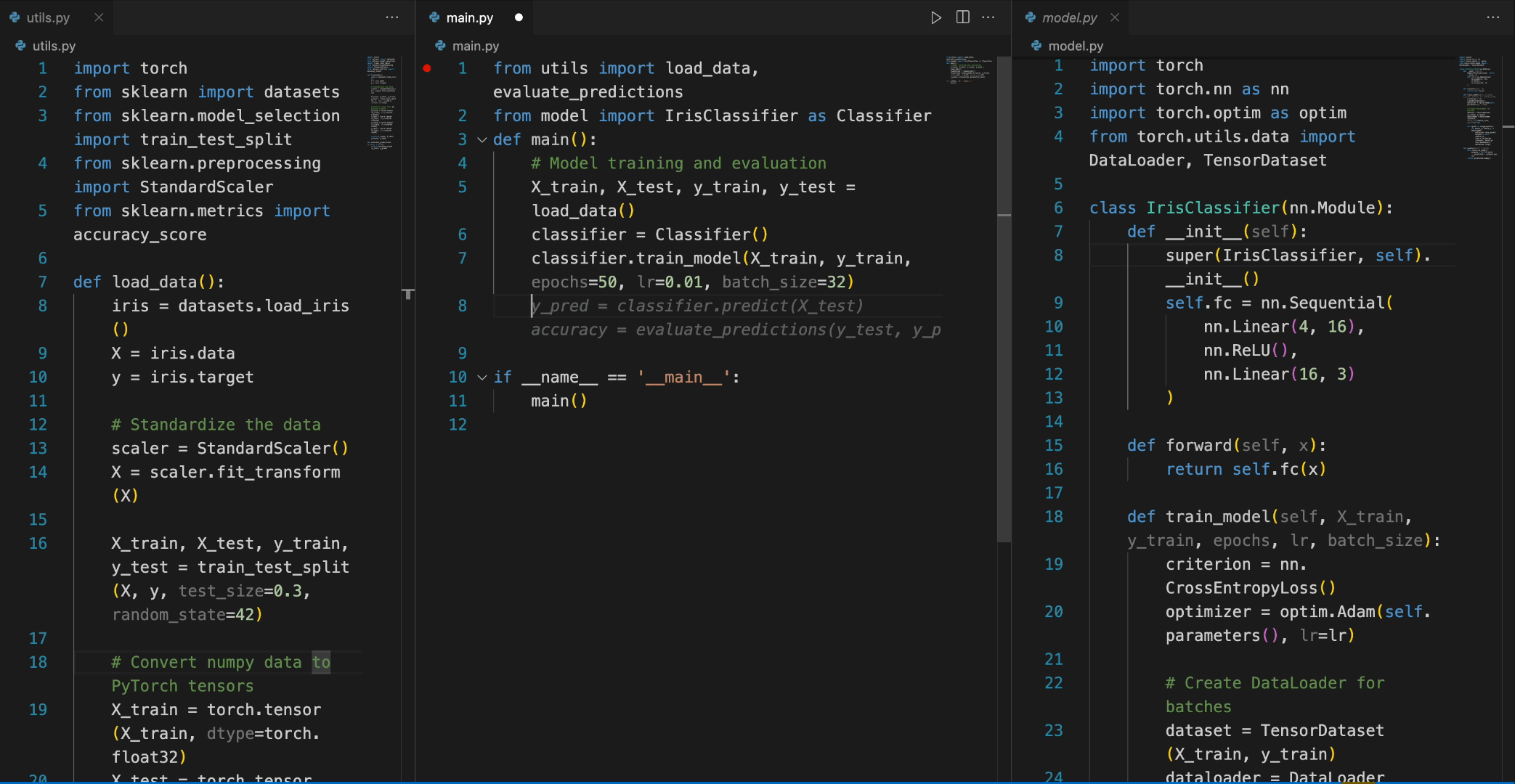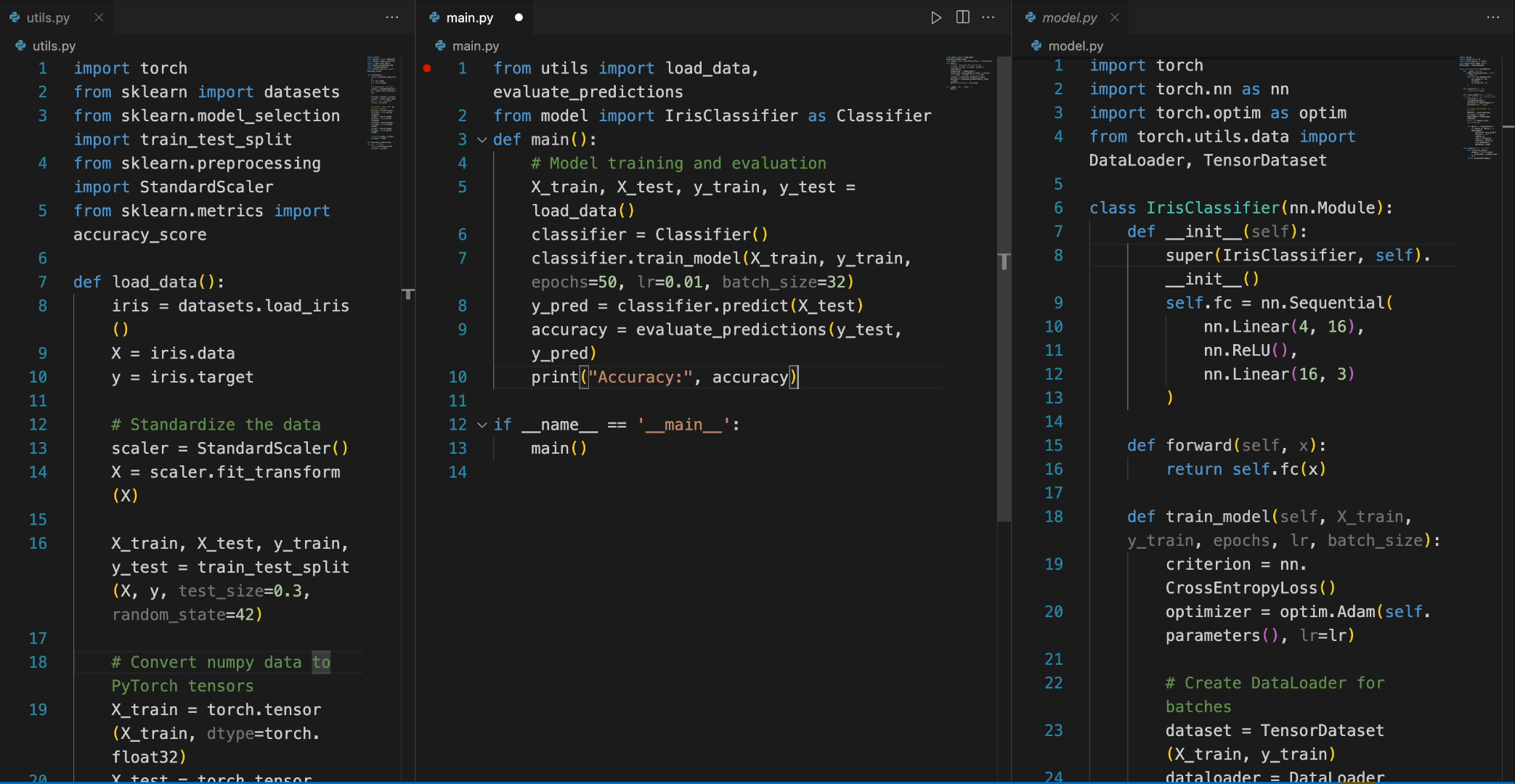
使用 DeepSeek Coder 相当直接,首先需要安装必要的依赖,运行以下命令:
pip install -r requirements.txt
然后,可以通过如下示例进行代码补全或插入:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
项目推介:
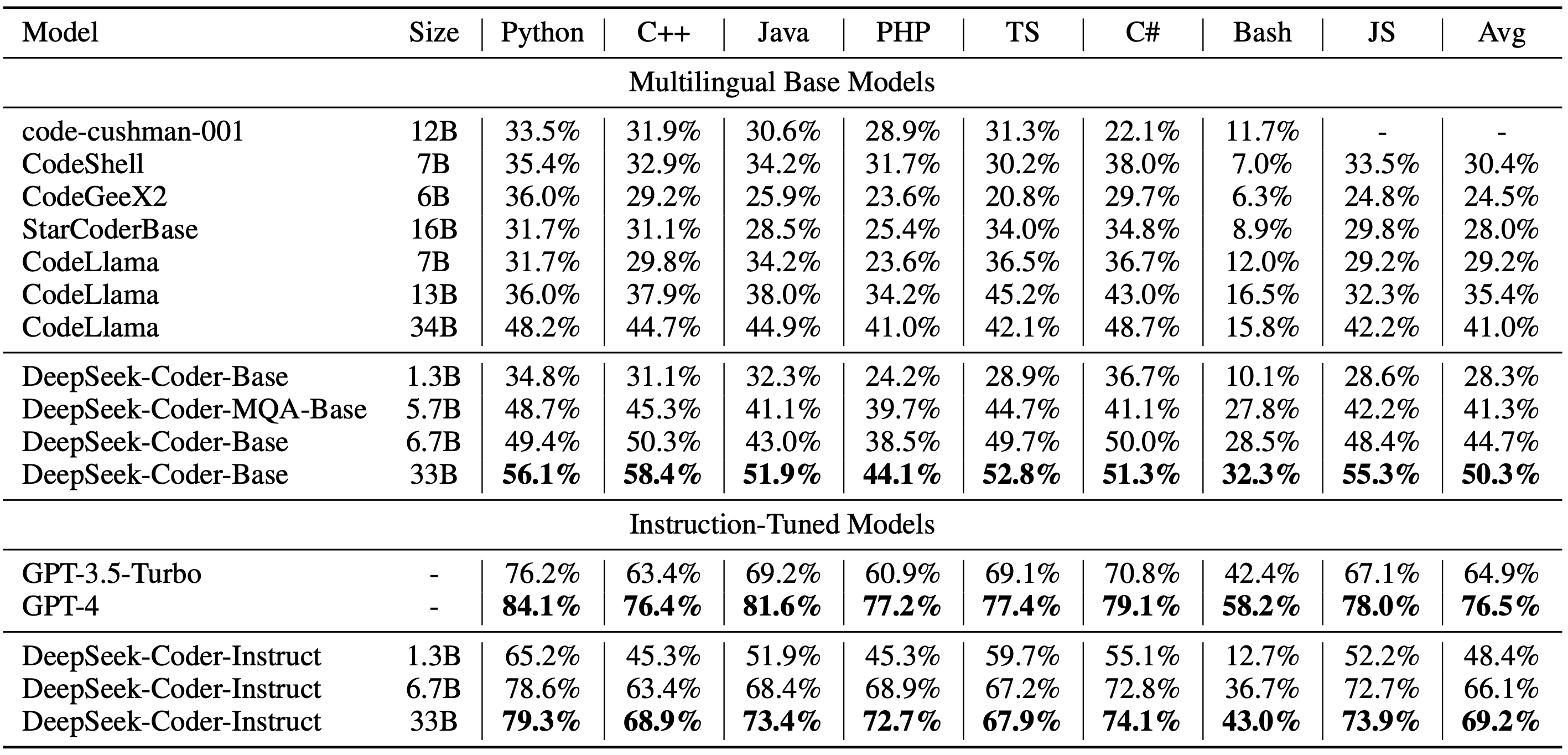
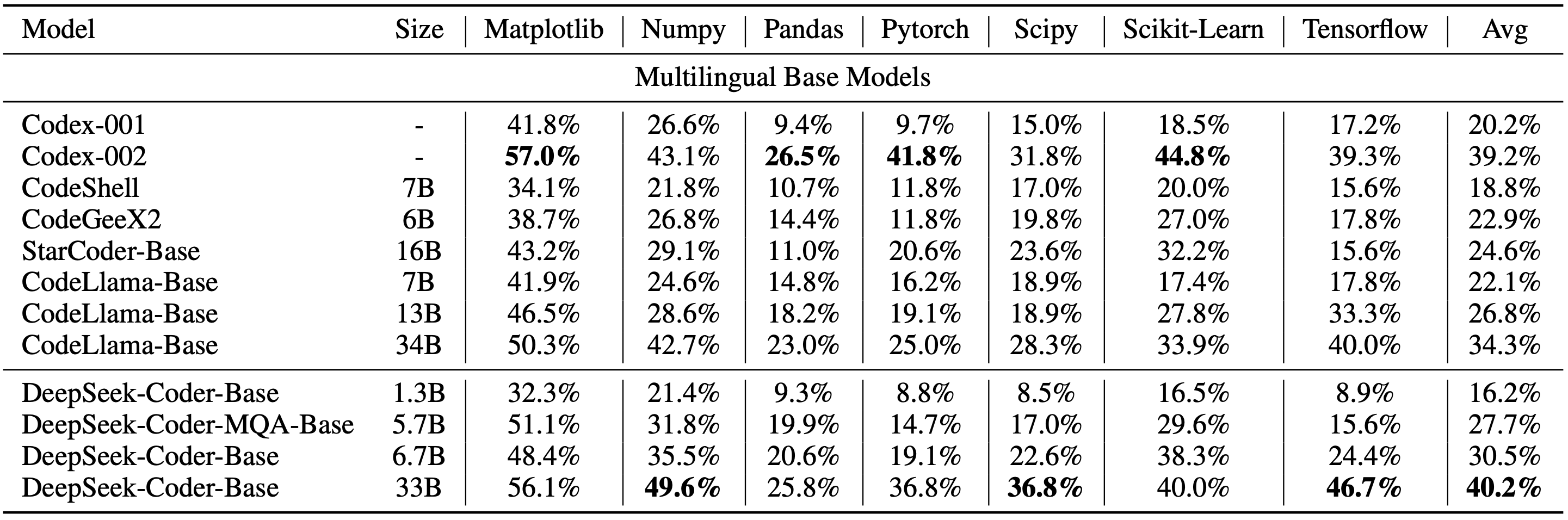
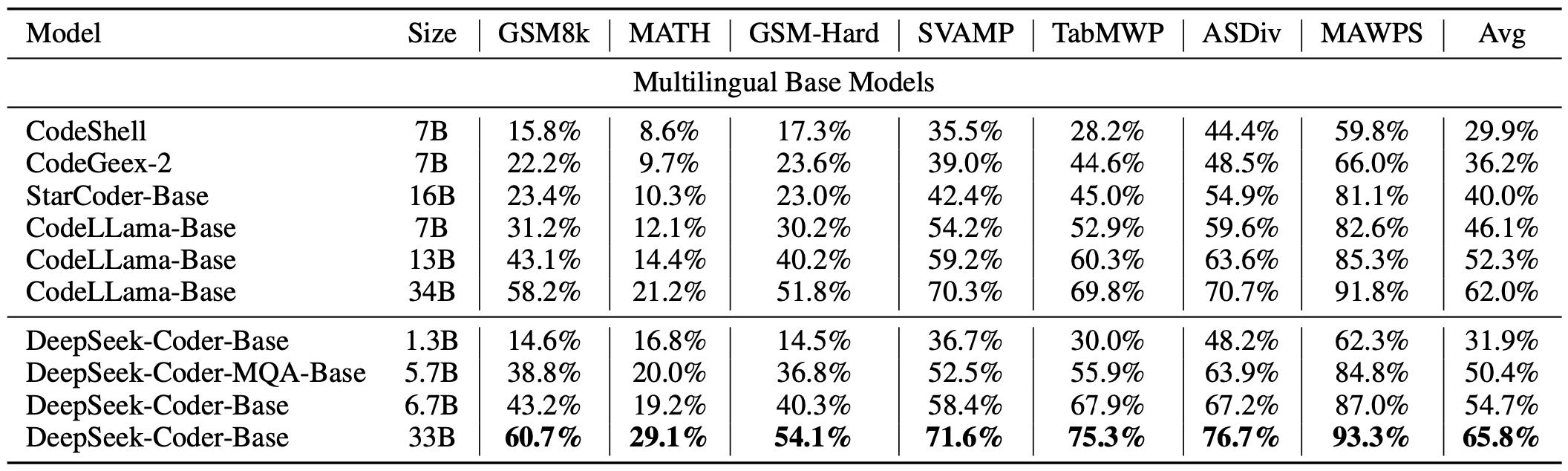
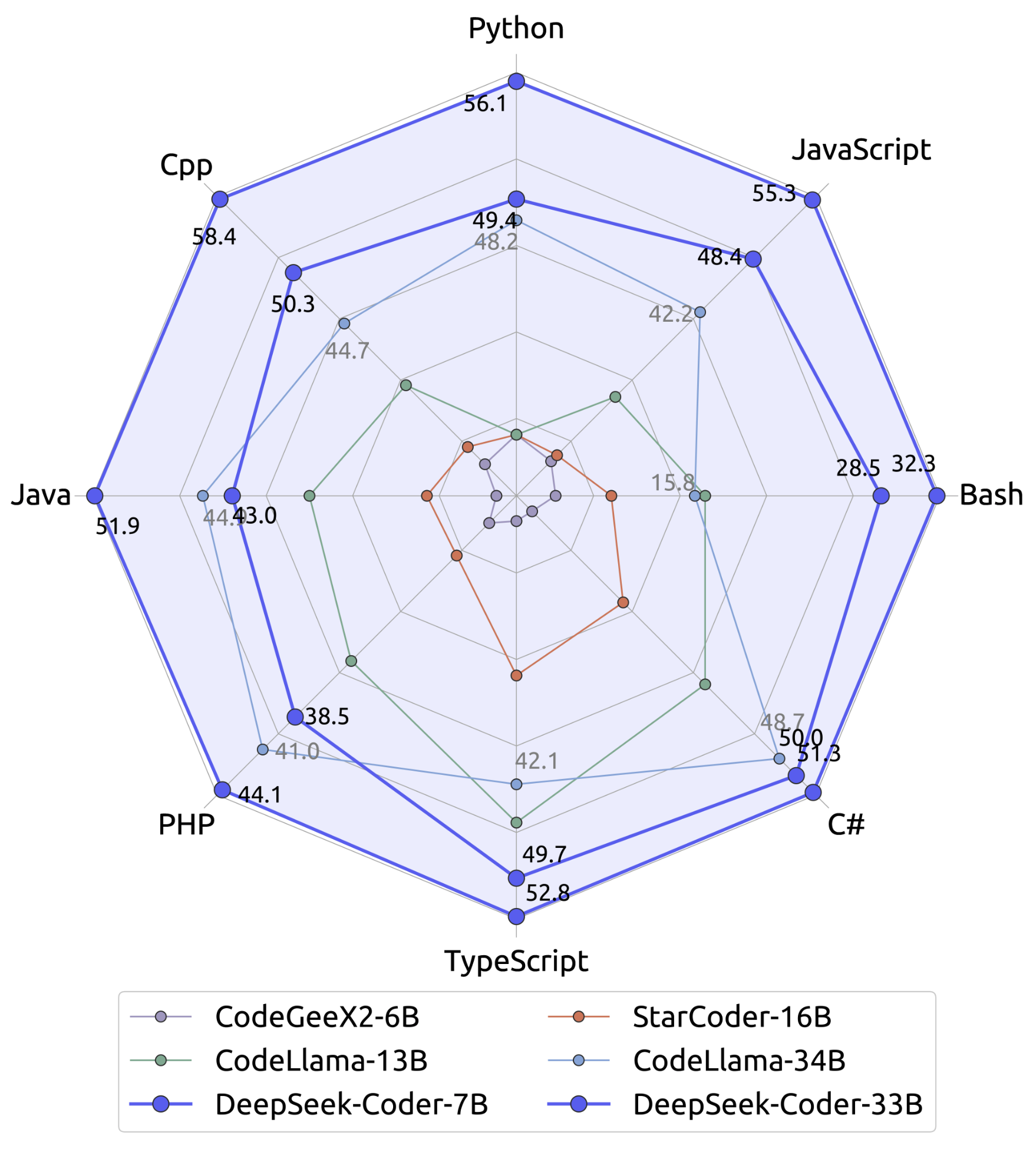
DeepSeek Coder 的开发活跃状态,以及具有高覆盖率的多语言编程语言支持,使其成为业界领先的代码自动生成工具之一。不仅如此,DeepSeek Coder 在 HumanEval、MultiPL-E、MBPP、DS-1000 和 APPS 等基准测试中展现出的卓越表现,证明了其在自然语言处理和代码生成领域的优势。无论是对于个人开发者还是大型企业,在提高开发效率、保证代码质量方面,DeepSeek Coder 都能发挥巨大作用。
DeepSeek Coder 的准确性、灵活性和可扩展性,使得它能够满足不同规模、不同语言项目的开发需求。无论您是在寻找提高个人编码效率的工具,还是需要为团队引入先进的代码自动生成技术,DeepSeek Coder 都将是您的理想选择。立即尝试 DeepSeek Coder,体验先进的 AI 在软件开发领域的强
以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/deepseek-ai/DeepSeek-Coder
开源项目作者:deepseek-ai
开源协议:MIT License
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。