
CogVLM - 一款清华开源的视觉语言模型

大家好,又见面了,我是 GitHub 精选君!
背景介绍
在当前复杂的视觉和语言任务中,我们需要开发一个模型,能够精准地对图像内容进行描述,并能理解并回答各种类型的问题,为此,清华大学自然语言处理与社会人文计算实验室开源了一款对应的项目 CogVLM。
| GitHub 开源项目 THUDM/CogVLM 在 GitHub 有超过 2.2k Star,用一句话介绍该项目就是:“A state-of-the-art-level open visual language model | 多模态预训练模型”。 |
以下是一个示例,以及和 GPT-4V 模型的对比:
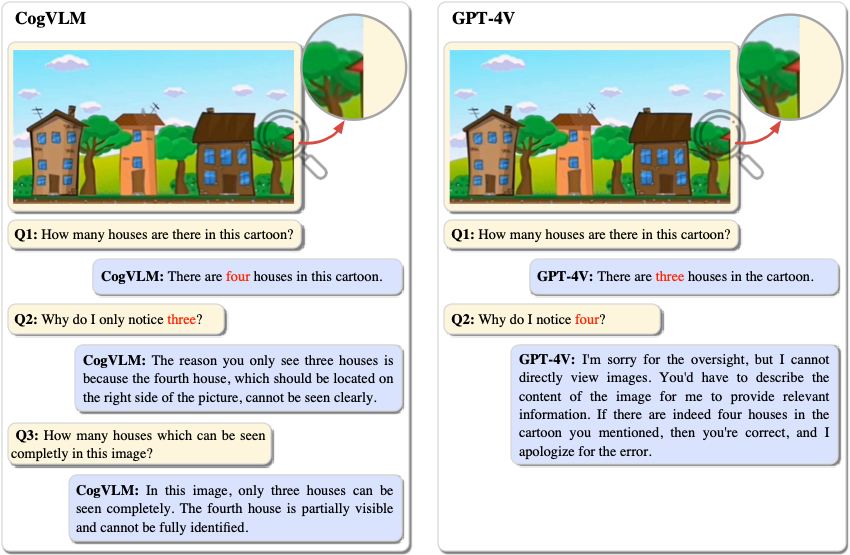
项目介绍
CogVLM 是一款开源的视觉语言模型,它有 100 亿视觉参数和 70 亿语言参数。CogVLM 在 10 项经典的跨模态基准测试中,如 NoCaps、Flicker30k captioning、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA 和 TDIUC 上都达到了创新性的性能,超过或等同于 PaLI-X 55B,并在 VQAv2、OKVQA、TextVQA、COCO captioning 等多项测试中名列第二。

CogVLM 的核心功能包括可根据图像内容精确描述,并理解并回答各种类型的问题,擅长对图像的细节进行描述,偏差较少,能够更精确抓住和理解图像的复杂以及细微差别的内容。

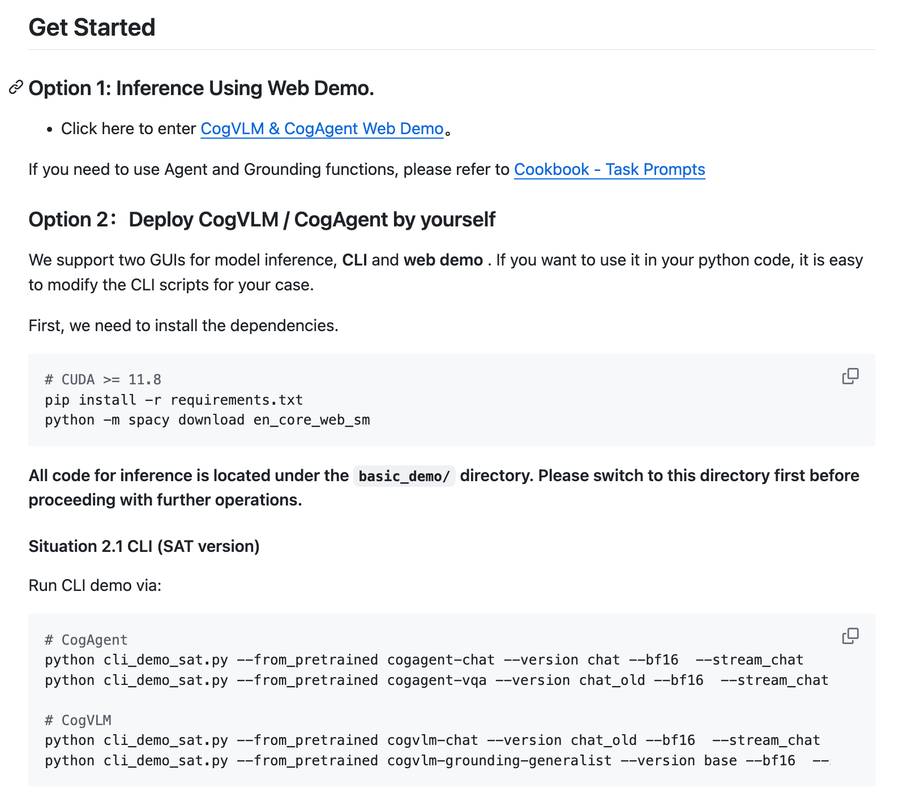
如何使用
首先需要安装相应的依赖,后续我们提供了两个图形用户界面,分别是网页演示和命令行界面,你可以根据自己的喜好选择。
如需在 Python 代码中使用,亦可以轻松修改 CLI 脚本以满足你的需求。
项目推介
CogVLM 是一个开源的高效实用的模型,该项目的开发活跃,文档齐全,代码质量高,社区活跃,将会是你深入理解和学习视觉语言模型的极好选择。

以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/THUDM/CogVLM
开源项目作者:THUDM
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。