
支持 90+ 语言的文档 OCR 工具包

大家好,又见面了,我是 GitHub 精选君!
背景介绍
随着科技的发展和全球化的进程,我们经常遇到需要处理多语种文档的情况,例如商业合同、学术论文等。然而,当前主流的 OCR(Optical Character Recognition 光学字符识别)工具或许可以精准地识别英文文本,但对其他语种的文本识别能力却略显薄弱。此外,真实世界的文档常常包含表格、图表等复杂布局,充斥着线性、非线性排列的文本,这也增加了文本识别的难度。因此,我们急需一个精确度高、支持多语种、能智能识别文本和表格的 OCR 工具。
今天要给大家推荐一个 GitHub 开源项目 surya,该项目在 GitHub 有超过 7.1k Star,一句话介绍该项目:Accurate line-level text detection and recognition (OCR) in any language.

项目介绍
Surya 一个多语言文档 OCR 工具包。其功能不仅包括精确的行级文本检测,还将解决更为复杂的文本识别和表格/图表识别问题。该项目对多种文档和语言作了优化,可应用于新闻、科学论文、扫描文件等众多场景。
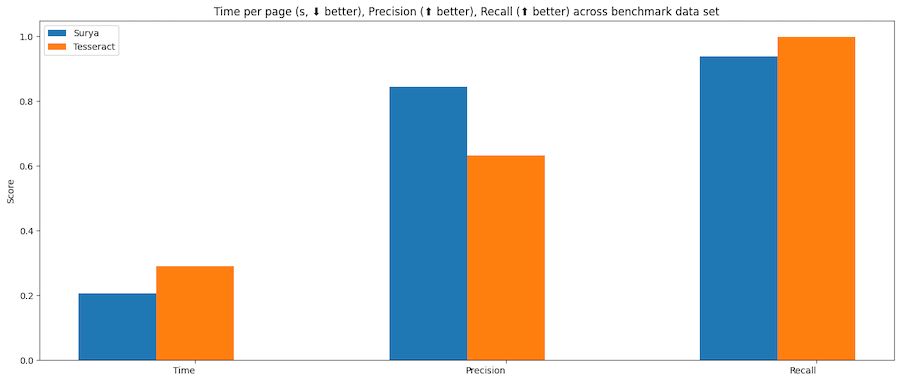
以下是 Surya 与 Tesseract 的性能对比:
如何使用
你需要有 python 3.9+ 版本和 PyTorch,然后你可以用命令 pip install surya-ocr 来安装。模型将在你第一次运行 surya 时自动下载。在运行程序时,可以通过环境变量来更改 surya/settings.py 中的设置。您还可以用以下代码检测文本行:
from PIL import Image
from surya.detection import batch_detection
from surya.model.segformer import load_model, load_processor
image = Image.open(IMAGE_PATH)
model, processor = load_model(), load_processor()
# predictions is a list of dicts, one per image
predictions = batch_detection([image], model, processor)
更多语言的代码示例项目也提供了:
项目推介
尽管 Surya 仍处于初期阶段,其精准度和效率在一定程度上已经超过了如 Tesseract 等其他 OCR 工具,且将逐渐开发出对文本识别和表格/图表识别的功能。
以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/VikParuchuri/surya
开源项目作者:VikParuchuri
开源协议:GNU General Public License v3.0
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。