
可以在任何地方运行的超小视觉语言模型

大家好,又见面了,我是 GitHub 精选君!
背景介绍
随着深度学习的发展,模型越来越大,而且需要大量的计算资源,这使得很多人难以使用。同时,尽管难度较大,但视觉和语言的结合对于许多实际应用来说却十分有用,例如对图像进行描述,回答关于图像的问题等。但这样的模型往往计算量大,运行速度慢,不易在移动设备上使用。
今天要给大家推荐一个 GitHub 开源项目 vikhyat/moondream,该项目在 GitHub 有超过 2.8k Star,一句话介绍该项目:tiny vision language model

项目介绍
moondream 是一个超小的视觉语言模型,不仅性能强大,而且可以在任何地方运行。 moondream2 是一个拥有 1.86B 参数的模型,它基于对 SigLIP 和 Phi 1.5 的权重进行初始化,提供了很好的性能。 它在各项评测中的表现都非常优秀,无论是 VQAv2、GQA 还是 TextVQA 等,都有相当高的表现。在模型设计上,它采用了自动化机器学习,使得模型可以自动从数据中学习并优化模型参数。这大大简化了模型的使用,用户无需对模型的运行细节进行了解,只需要输入图片,并给出相关的问题,模型就能自动给出相应的回答。
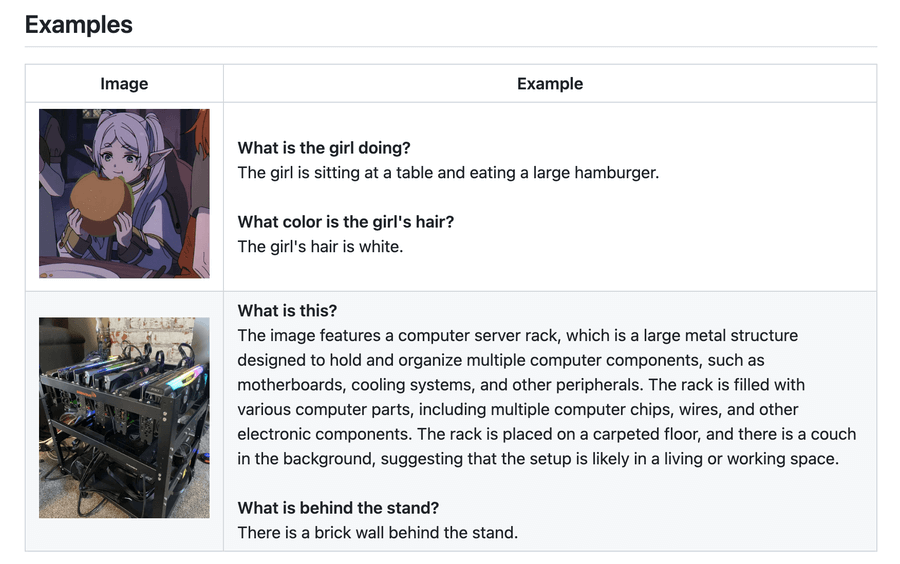
以下是两个示例:
如何使用
使用 moondream 模型非常的简单,首先,需要安装 transformers、timm 和 einops 包。
pip install transformers timm einops
然后,使用 AutoModelForCausalLM 和 AutoTokenizer 来加载模型和字典。接着,我们可以使用 model.encode_image(image) 来对图片进行编码,然后,使用 model.answer_question(enc_image, “Describe this image.”, tokenizer) 来对图片进行描述。
以下是对应的示例代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
model_id = "vikhyatk/moondream2"
revision = "2024-04-02"
model = AutoModelForCausalLM.from_pretrained(
model_id, trust_remote_code=True, revision=revision
)
tokenizer = AutoTokenizer.from_pretrained(model_id, revision=revision)
image = Image.open('<IMAGE_PATH>')
enc_image = model.encode_image(image)
print(model.answer_question(enc_image, "Describe this image.", tokenizer))
项目推介
moondream 目前在GitHub上活跃度非常高,项目发布后得到了大量开发者的关注和使用。除此之外,它也在 Hugging Face的模型库中有详细介绍,对于感兴趣的开发者来说,值得一试。
以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/vikhyat/moondream
开源项目作者:vikhyat
开源协议:
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。