
ChatGLM3 - 智谱 AI 和清华大学 KEG 实验室联合发布的新一代对话预训练模型

大家好,又见面了,我是 GitHub 精选君!
背景介绍
在当今以信息为主导的社会,人们从未像现在这样对语言对话技术有着如此高的期待。无论是用于家居语音助手,还是在线客户服务,甚至是用于复杂任务的机器人对话系统,高效准确的语言模型处理和理解能力都是至关重要的。然而,现有的对话语言模型往往不具备足够的效率和精度,且部署门槛较高,难以适应各类复杂场景。这使得我们对更加强大,完整并易于使用的对话语言模型有着迫切的需求。
| 今天要给大家推荐一个 GitHub 开源项目 THUDM/ChatGLM3,该项目在 GitHub 有超过 4.9k Star,用一句话介绍该项目就是:“ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型”。 |
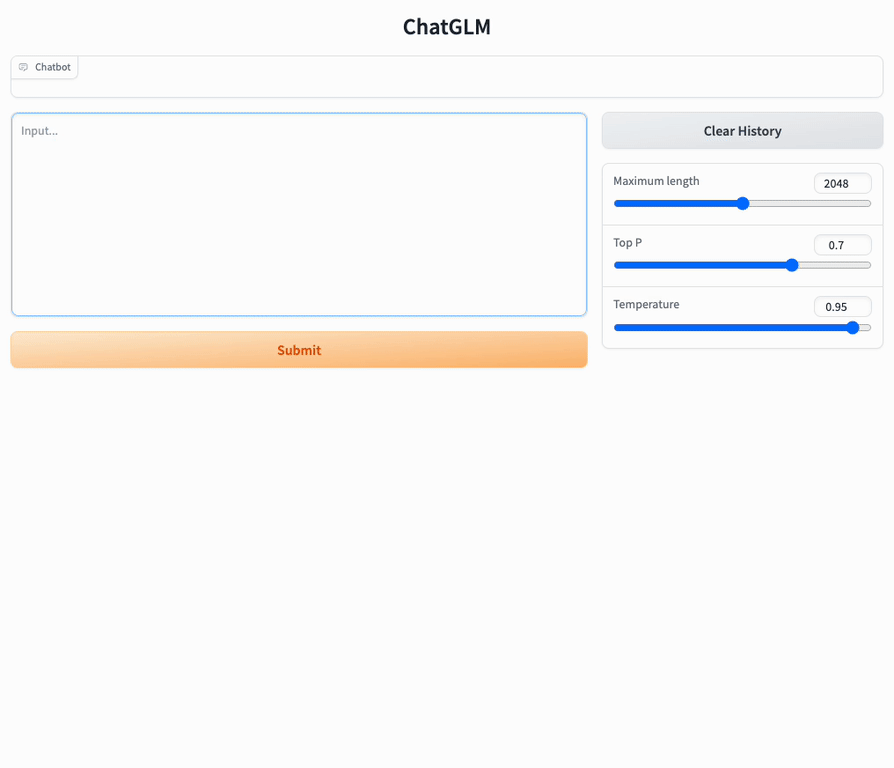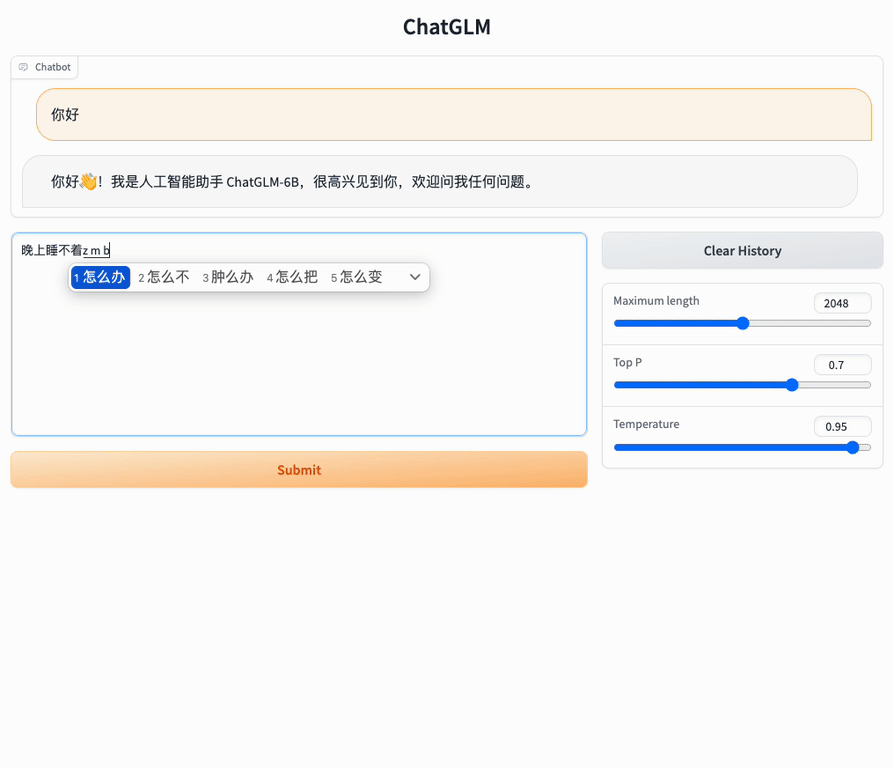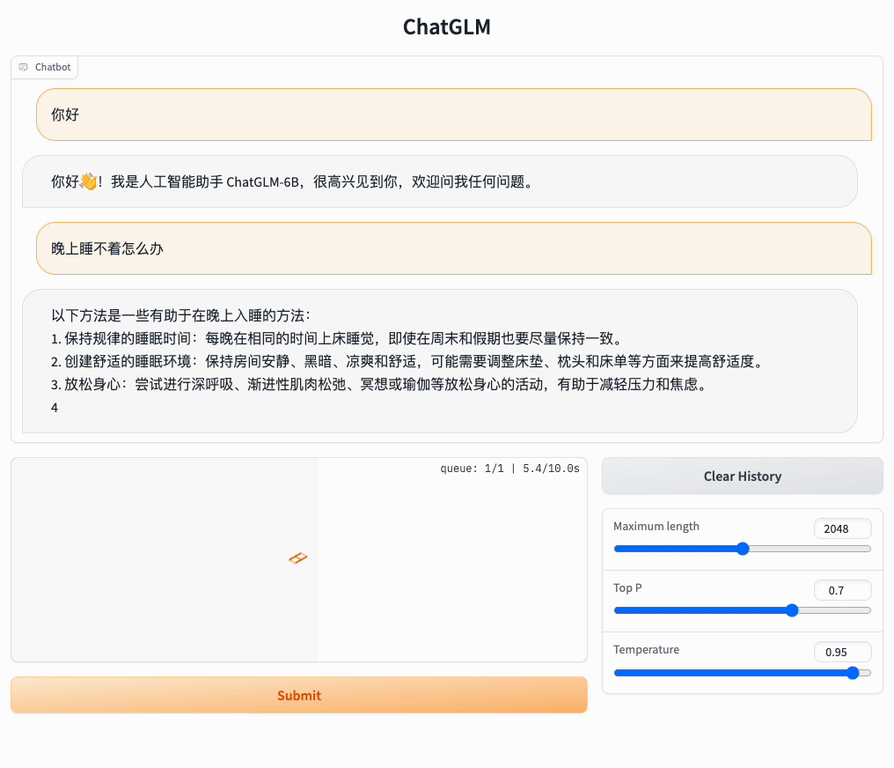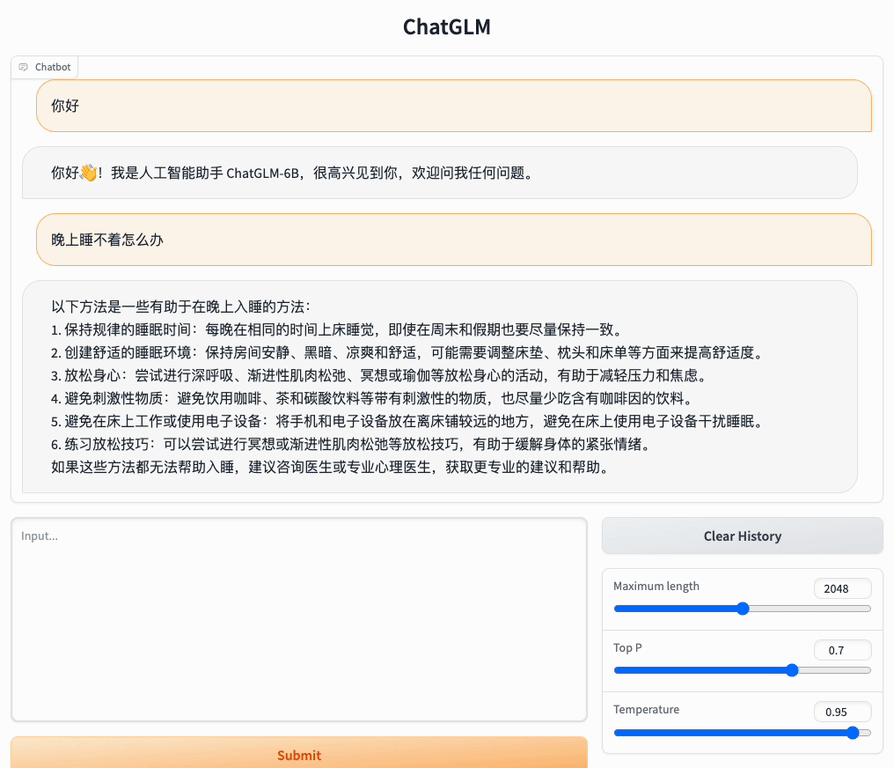
以下是一个使用示例:
项目介绍
ChatGLM3 是智谱 AI 和清华大学 KEG 实验室联合发布的新一代对话预训练模型。它引入了更强大的功能并将其应用于 ChatGLM3-6B,这是 ChatGLM3 系列中的开源模型。
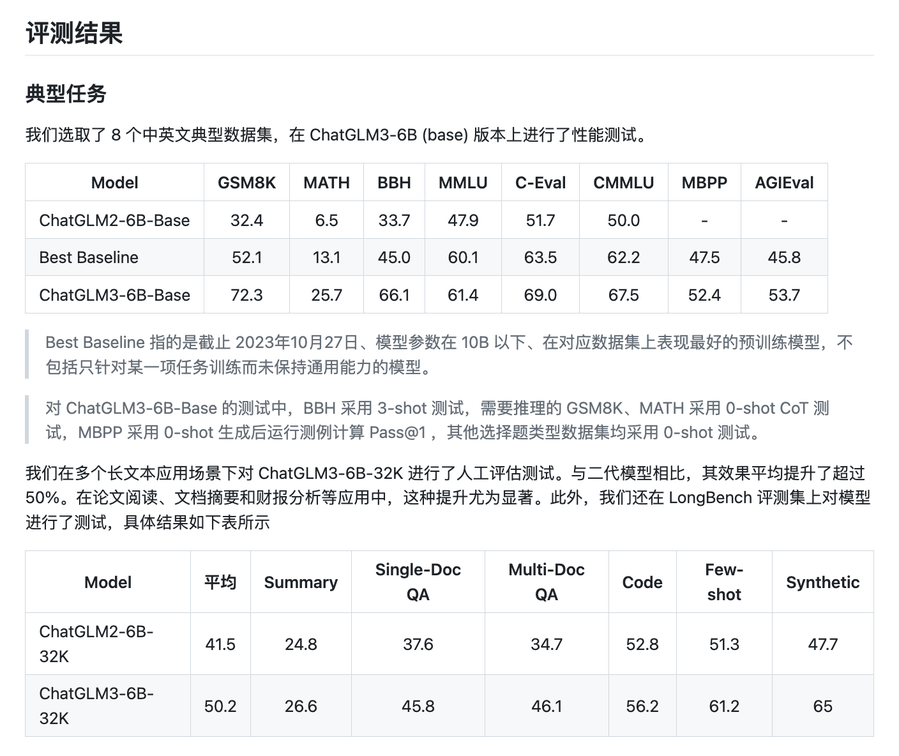
首先,ChatGLM3-6B 的基础模型在训练数据,训练步数和训练策略等方面都作了全面优化,从而在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,能在语义、数学、推理、代码、知识等不同角度的数据集上展现出最强的性能。
其次,ChatGLM3-6B 原生支持工具调用、代码执行和 Agent 任务等复杂场景,旨在帮助用户更轻松地处理各种问题。
除此之外,ChatGLM3-6B 还开源了全面的模型列表,包括基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K,以推动大模型技术的发展。
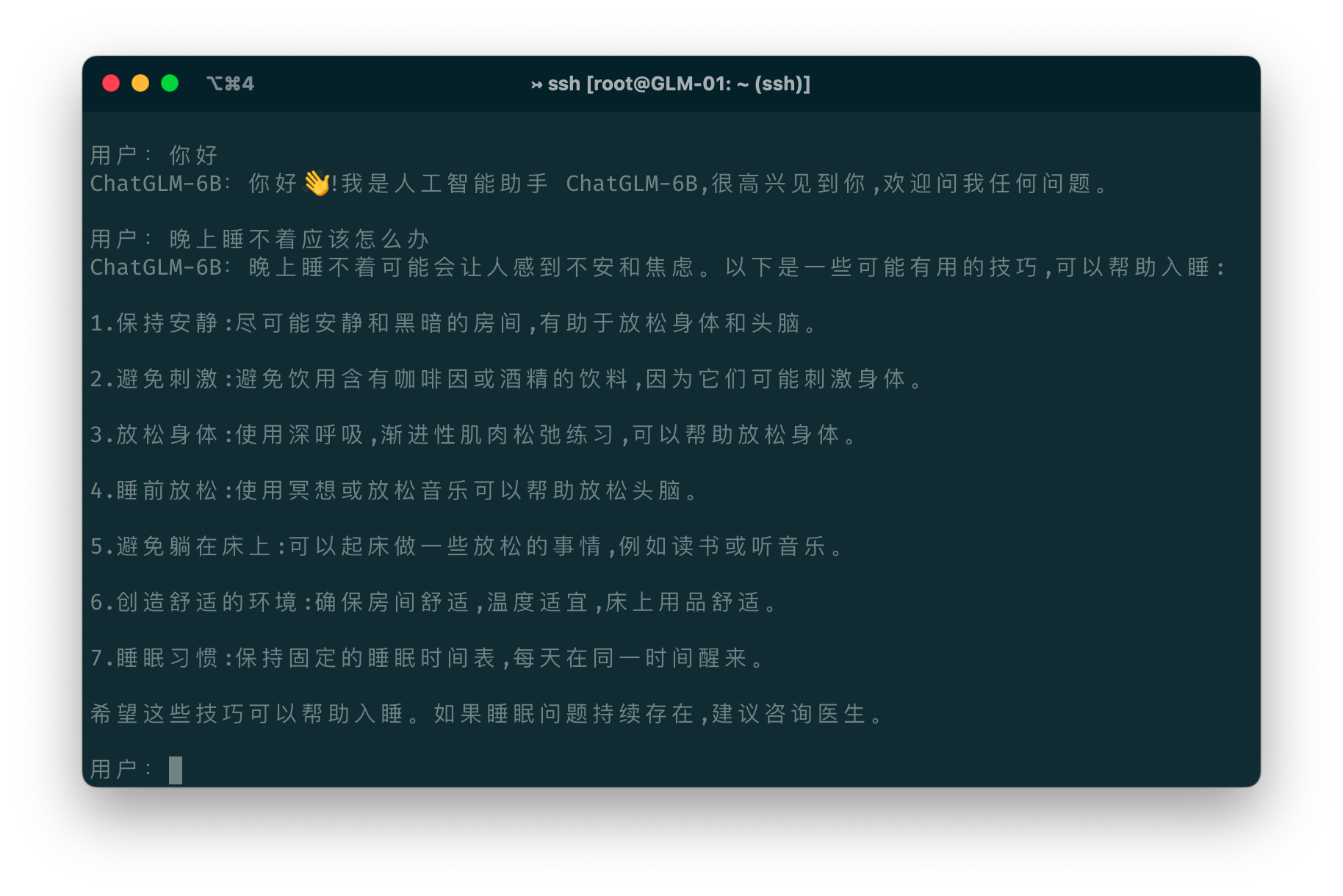
命令行的使用示例:
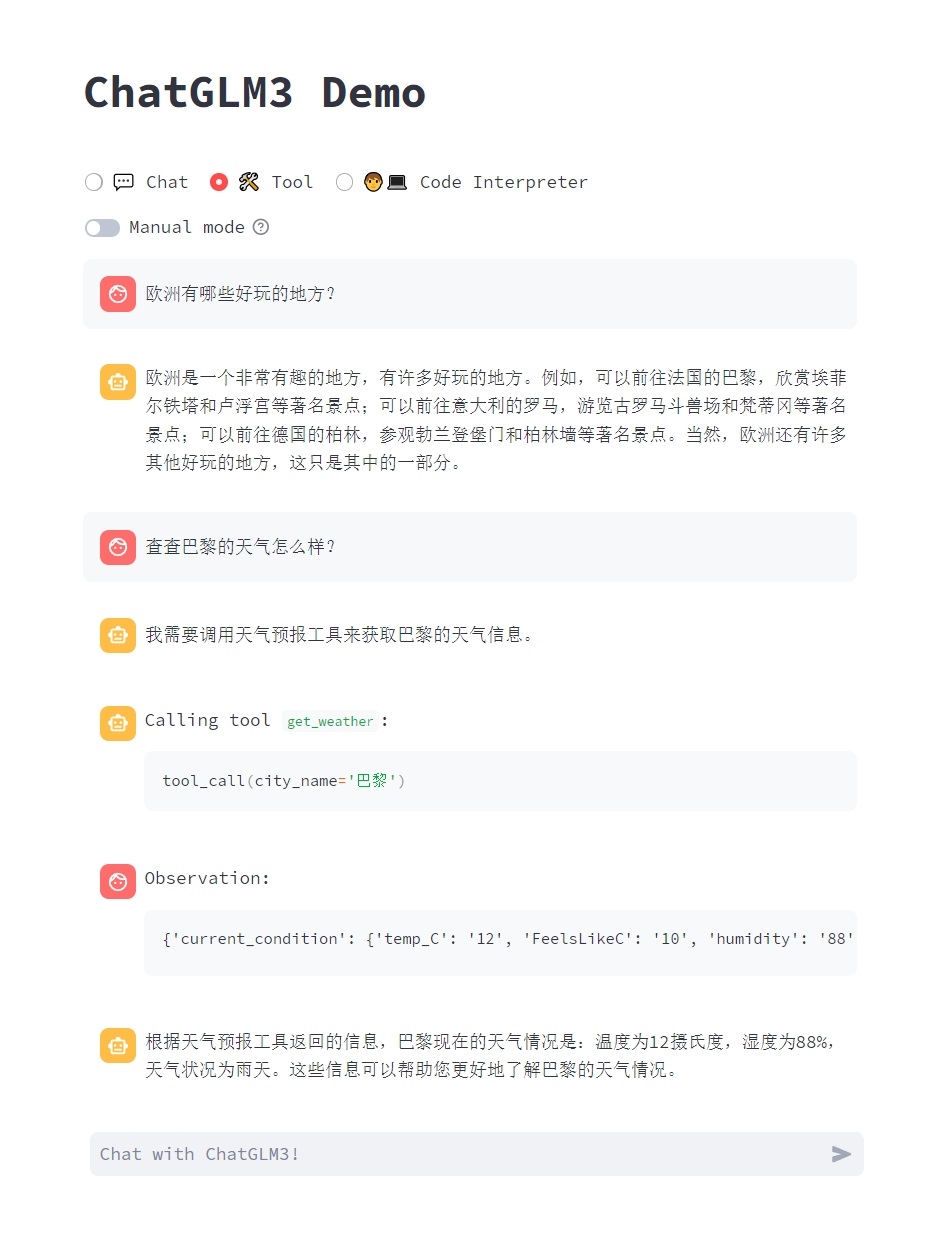
工具调用的示例:
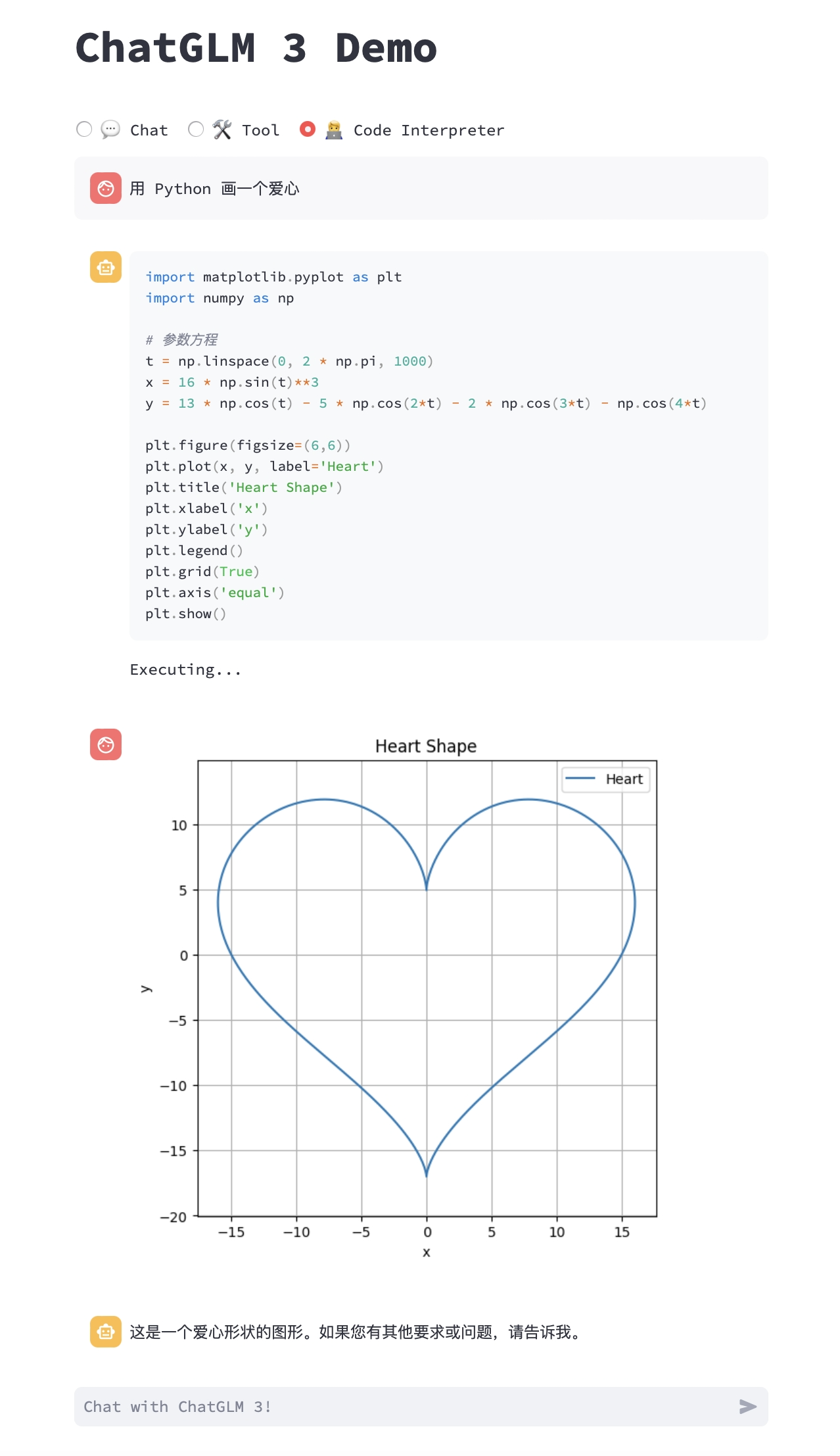
生成代码与执行的示例:
如何使用
首先,你需要下载此仓库并安装相关的依赖,包括 transformers 和 torch 库,具体操作如下:
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
pip install -r requirements.txt
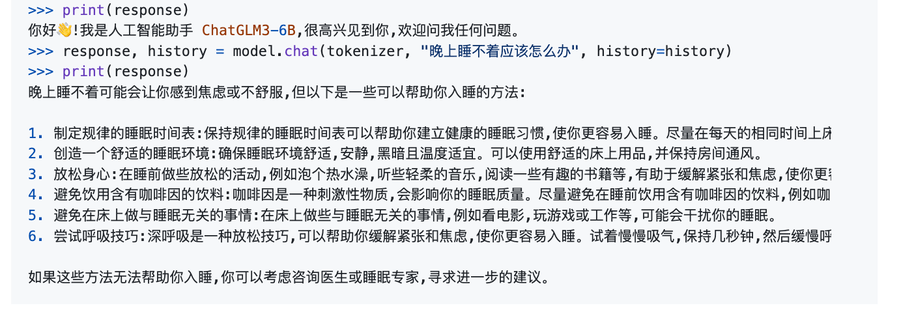
然后,你就可以调用 ChatGLM 模型来生成对话了。例如:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
最后,模型会返回生成回答字符串。
项目推荐
ChatGLM3 在众多知名论文和大赛中都已经展现出其优异的性能,并且目前在 chatglm.cn 网站上体验 ChatGLM 模型的用户已经超过数千人,应用于范围涉及日常生活、科技研究、教育辅导等众多领域。
以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/THUDM/ChatGLM3
开源项目作者:THUDM
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。