
微软开源专注加快大模型推断速度

大家好,又见面了,我是 GitHub 精选君!
背景介绍
在大规模语言模型推理过程中,我们经常会面临几个问题:如何加快语言模型的推理速度;如何增强语言模型对关键信息的感知;如何压缩 prompt 提示和 KV-Cache。这些问题让人头痛,很多解决起来需要很多人力和资源投入。
今天要给大家推荐一个微软开源的项目 LLMLingua,该项目在 GitHub 有超过 1.2k Star,用一句话介绍该项目就是:“To speed up LLMs’ inference and enhance LLM’s perceive of key information, compress the prompt and KV-Cache, which achieves up to 20x compression with minimal performance loss. ”。
项目介绍
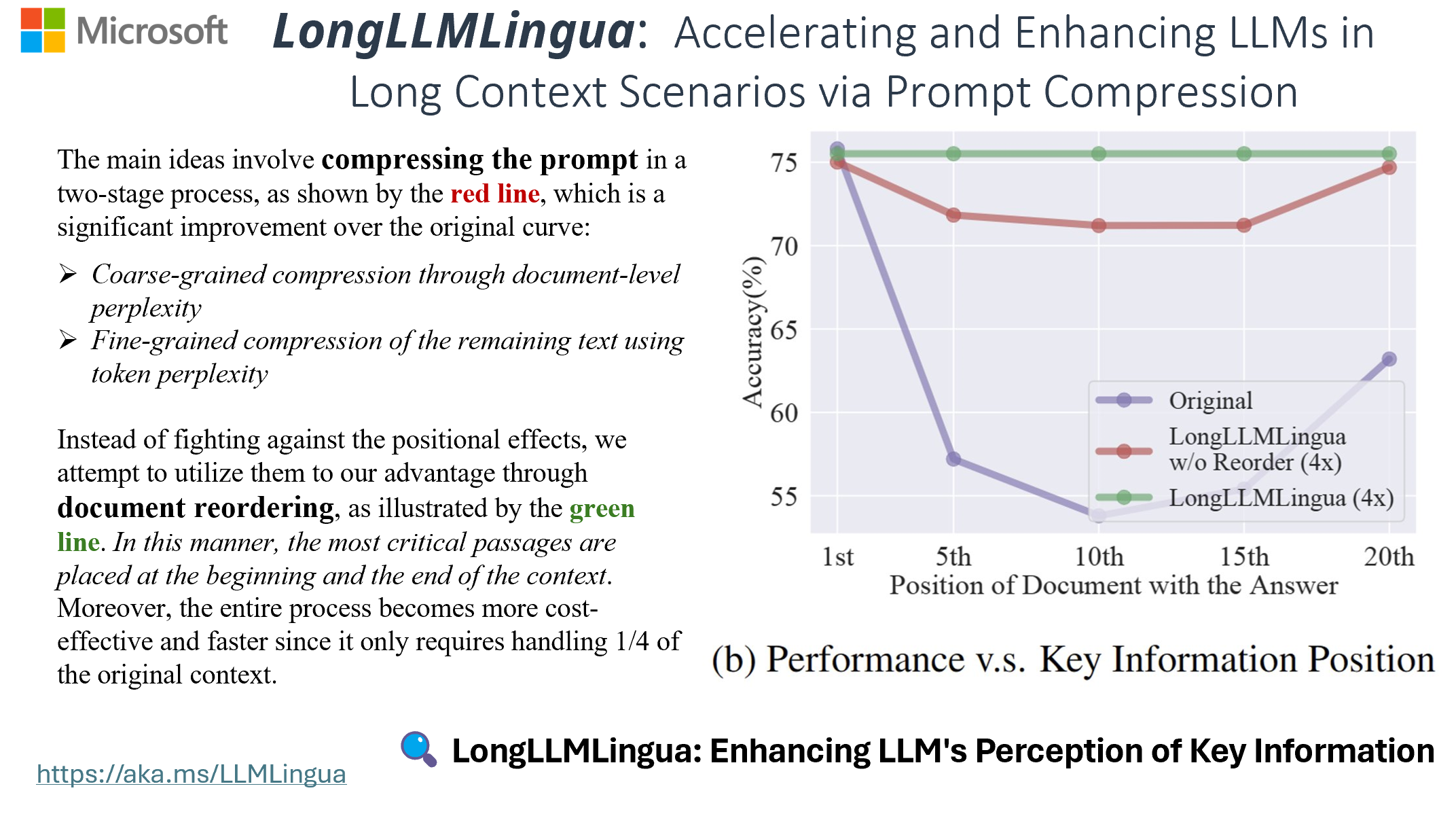
LLMLingua 是一个由微软开发的专注于加快大规模语言模型 ( LLMs ) 的推断速度和增强模型对关键信息感知的开源项目。通过创新的方式压缩提示和 KV-Cache,LLMLingua 能达到高达 20 倍的压缩效果,而且性能损失微乎其微。无论是 GPT2-samll,还是 LLaMA-7B,LLMLingua 都能有效地识别并移除非必需的提示字符串,从而实现高效的大规模语言模型推断。在微软的 LLMLingua 项目中,还推出了 LongLLMLingua 工具,它专门解决 LLMs 中在交流的中部模型迷失的问题,增强了长上下文信息处理的能力。只使用 1/4 的 Token,就可以提高达 21.4% 的 RAG 性能。
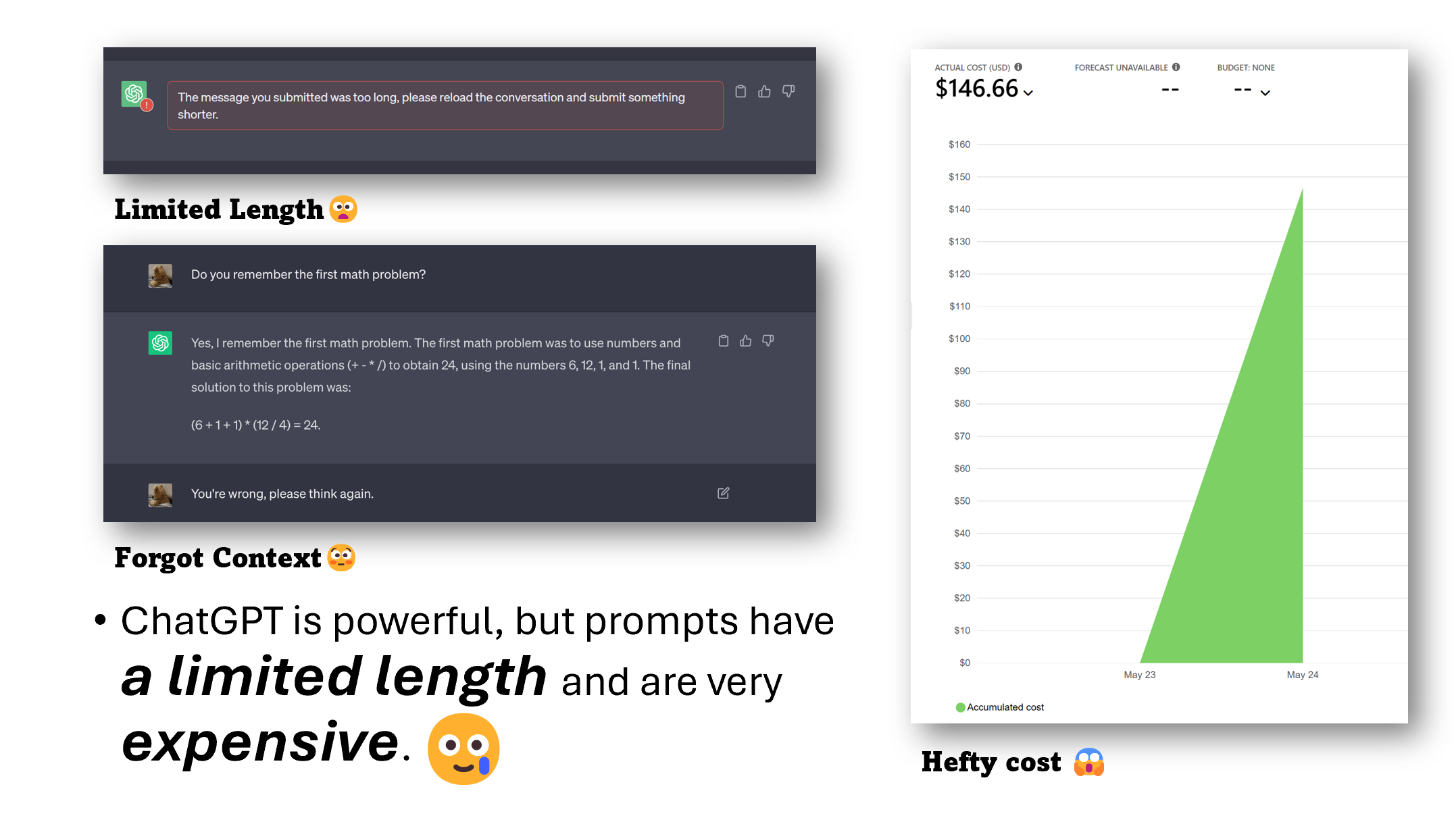
当前大模型的应用现状:
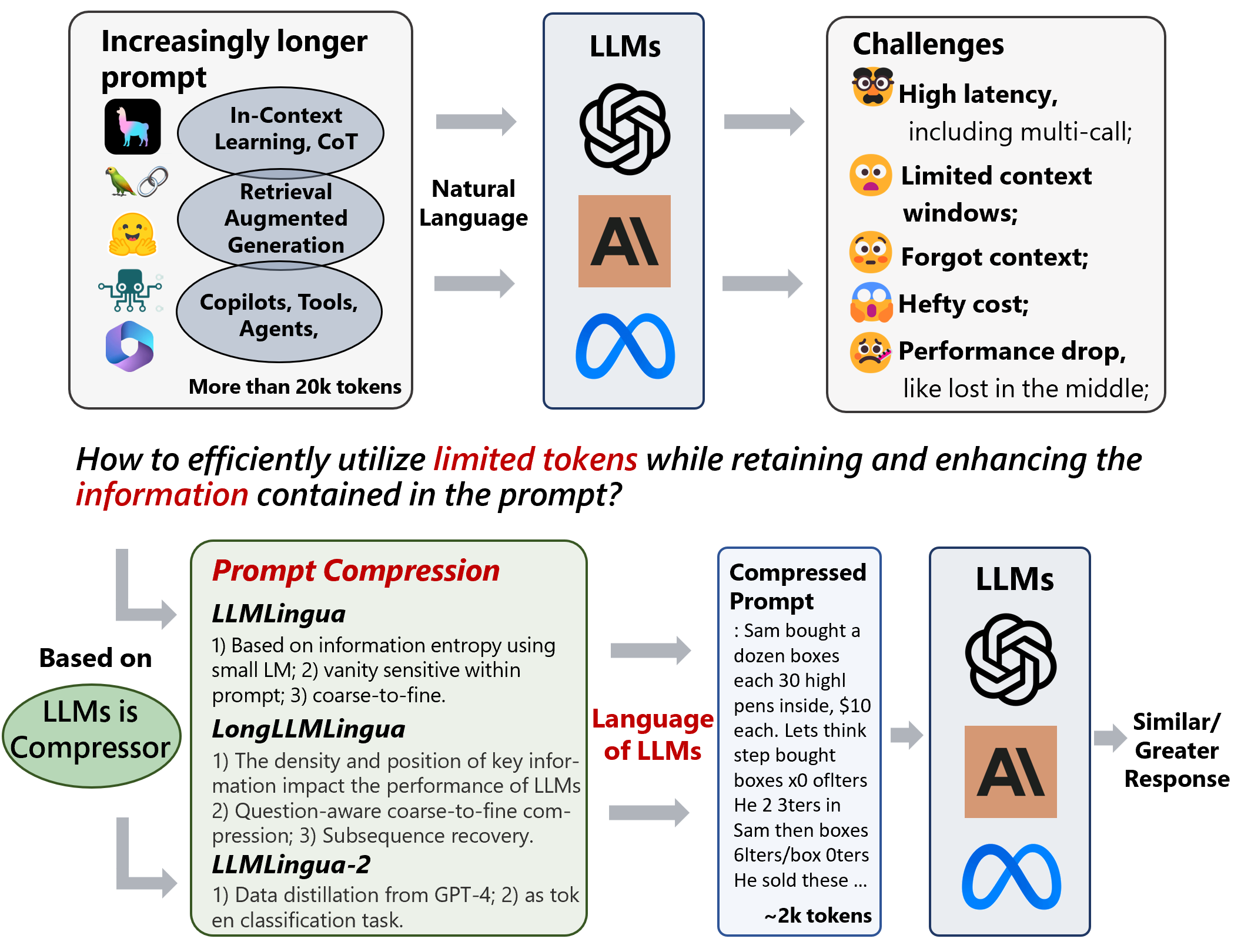
LLMLingua 的架构:
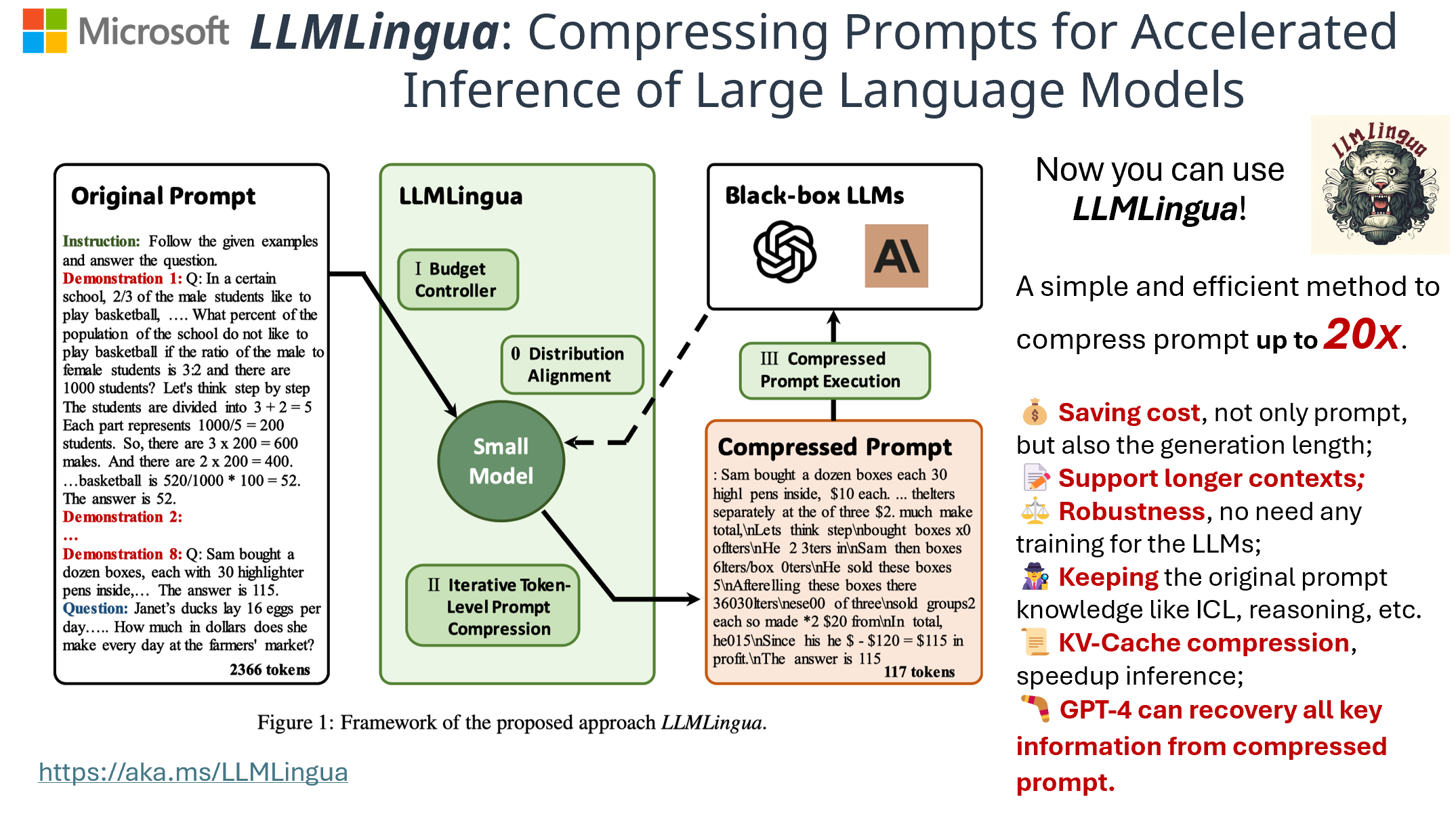
LLMLingua 的效果:
如何使用
使用 LLMLingua 的过程非常简单,通过 pip 即可快速安装,运行 pip install llmlingua。然后,你就可以使用(Long)LLMLingua 来压缩你的提示了,代码如下:
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
compressed_prompt = llm_lingua.compress_prompt(prompt, instruction="", question="", target_token=200)
# > {'compressed_prompt': 'Question: Sam bought a dozen boxes, each with 30 highlighter pens inside, for $10 each box. He reanged five of boxes into packages of sixlters each and sold them $3 per. He sold the rest theters separately at the of three pens $2. How much did make in total, dollars?\nLets think step step\nSam bought 1 boxes x00 oflters.\nHe bought 12 * 300ters in total\nSam then took 5 boxes 6ters0ters.\nHe sold these boxes for 5 *5\nAfterelling these boxes there were 3030 highlighters remaining.\nThese form 330 / 3 = 110 groups of three pens.\nHe sold each of these groups for $2 each, so made 110 * 2 = $220 from them.\nIn total, then, he earned $220 + $15 = $235.\nSince his original cost was $120, he earned $235 - $120 = $115 in profit.\nThe answer is 115',
# 'origin_tokens': 2365,
# 'compressed_tokens': 211,
# 'ratio': '11.2x',
# 'saving': ', Saving $0.1 in GPT-4.'}
## Or use the phi-2 model,
## Before that, you need to update the transformers to the github version, like pip install -U git+https://github.com/huggingface/transformers.git
llm_lingua = PromptCompressor("microsoft/phi-2")
## Or use the quantation model, like TheBloke/Llama-2-7b-Chat-GPTQ, only need <8GB GPU memory.
## Before that, you need to pip install optimum auto-gptq
llm_lingua = PromptCompressor("TheBloke/Llama-2-7b-Chat-GPTQ", model_config={"revision": "main"})
项目推介
作为微软发布的开源项目,LLMLingua 是由经验丰富的开发者团队开发的,他们定期更新和维护此项目,致力于为 LLMLingua 提供最新的功能和改进。根据多篇学术论文的研究表明,LLMLingua 在压缩提示、加速推断、增强大规模语言模型的信息处理能力等方面取得了显著的成果。
以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/microsoft/LLMLingua
开源项目作者:microsoft
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。