
多模态视觉语言模型 Mini-Gemini

大家好,又见面了,我是 GitHub 精选君!
背景介绍
随着大数据和人工智能技术的快速发展,多模态视觉语言模型(Multi-modality Vision Language Models)已成为近年来研究的热点。这类模型通过融合图像和文本信息,能够更好地理解和生成复杂的视觉语言内容,广泛应用于图像标注、视觉问答、内容生成等领域。然而,开发和训练这类高效、精确且可扩展的多模态模型仍面临巨大挑战,包括如何处理不同模态间的复杂交互、如何提高模型的理解和生成能力、以及如何处理巨大的模型尺寸和计算成本等问题。
今天要给大家推荐一个 GitHub 开源项目 dvlab-research/MiniGemini,该项目在 GitHub 有超过 2.5k Star,一句话介绍该项目:Official implementation for Mini-Gemini

项目介绍
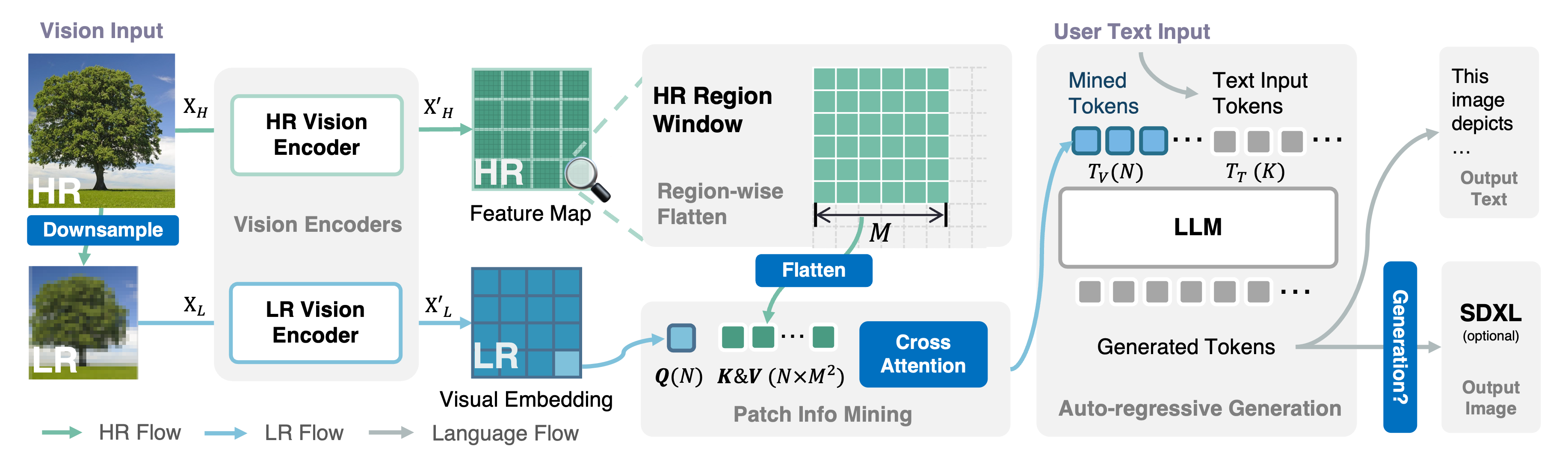
Mini-Gemini 项目提供了一系列从 2B 到 34B 的密集型和 MoE 大型语言模型(LLMs),这些模型能够同时处理图像理解、推理和生成。Mini-Gemini 基于 LLaVA 构建,采用双重视觉编码器,提供低分辨率视觉嵌入和高分辨率候选;提出了补丁信息挖掘,以执行高分辨率区域与低分辨率视觉查询之间的补丁级挖掘;并使用 LLM 将文本与图像结合起来,同时进行理解和生成。该项目已经公开了论文、在线演示、代码、模型和数据,为研究人员和开发者提供了宝贵的资源。
以下是模型的构成:
如何使用
1、克隆仓库:
git clone https://github.com/dvlab-research/MiniGemini.git
2、安装所需包:
conda create -n minigemini python=3.10 -y
conda activate minigemini
cd MiniGemini
pip install --upgrade pip
pip install -e .
3、若进行训练案例,需安装额外包:
pip install ninja
pip install flash-attn --no-build-isolation
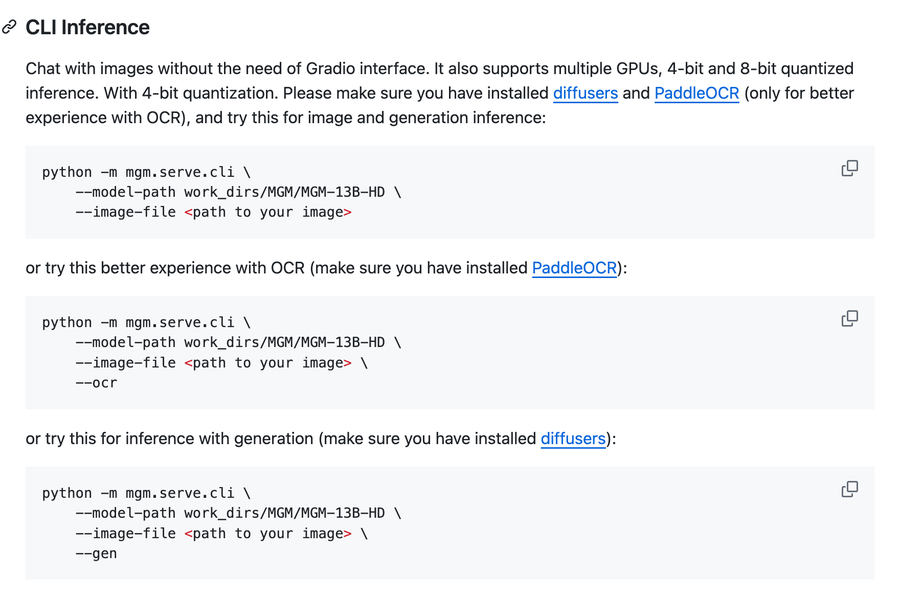
以下是一些命令行使用示例:
项目推介
Mini-Gemini 是多模态视觉语言模型领域的一次重要突破,它不仅涵盖了从语言到图像的综合理解和生成能力,而且通过提供预训练和微调模型,极大地简化了多模态任务的开发流程。
以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/dvlab-research/MiniGemini
开源项目作者:dvlab-research
开源协议:
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。