
使用 Go 开发但通过 JS 编写规则的爬虫工具

大家好,又见面了,我是 GitHub 精选君!
背景介绍
在现代的网络环境中,你时常会需要抓取网络页面上的各类数据。 或许你是一个业务分析师,需要收集大量的开放数据进行数据建模,或许你是内容研究员,需要收集新闻资讯进行文本分析。不论你身处何种情景,你都可能会面临如何高效、准确地从网页上抓取到你需要的信息,特别是在复杂且动态更新的网页环境中,完成这项工作将显得尤其困难。
今天要给大家推荐一个 GitHub 开源项目 philippta/flyscrape,该项目在 GitHub 有差不多 1000 Star,一句话介绍该项目:A standalone and scriptable web scraper in Go

项目介绍
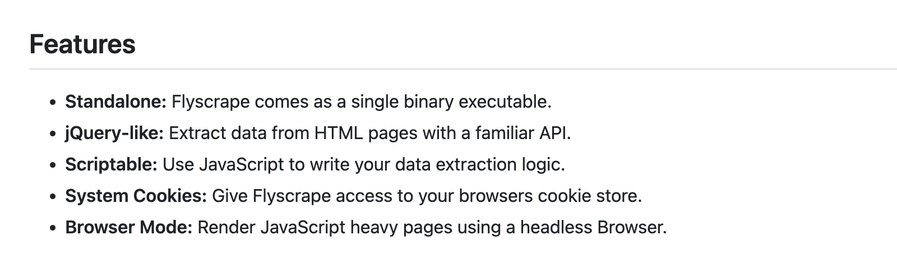
flyscrape 是一个使用 Go 语言开发的独立且可脚本化的网络爬虫工具,它将 Go 语言的速度与 JavaScript 的灵活性相结合,让你可以更专注于数据提取。flyscrape 具有高度的配置性,提供了 13 项设置供你调整你的抓取器。它是一个独立的可执行文件,无需依赖其他任何 npm 包。此外,它有着简明的 API,可通过 JavaScript 脚本指定你的数据提取逻辑,也有请求缓存功能,让你在已经抓取的网站上再次运行你的脚本。flyscrape 提供文件下载功能,并有开发模式让你获取快速反馈,优化你的抓取脚本。
如何使用
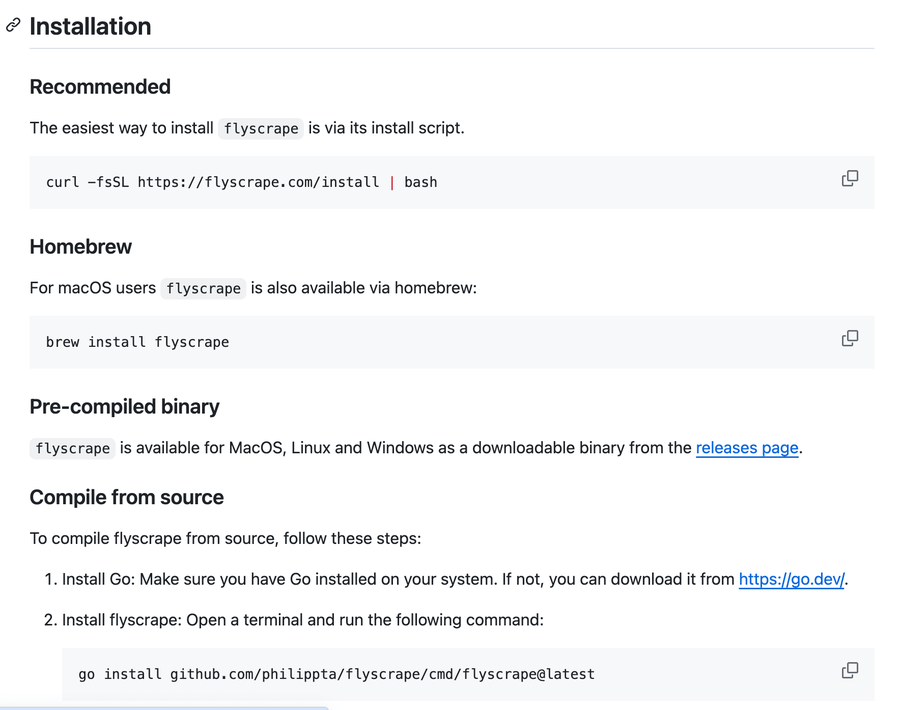
安装 flyscrape 非常方便,你可以通过其安装脚本直接安装,只需要在命令行执行相应命令。此外,macOS 用户还可以通过 homebrew 进行安装。另外,该项目还在发布页面提供了已预编译的可执行文件,支持 MacOS,Linux 和 Windows 平台。当然你也可以通过源代码自行编译。
使用 flyscrape 更简单,你只需要编写一段 JavaScript,将你的抓取规则及所需字段进行配置并导出,然后在命令行中运行命令即可开始抓取。
flyscrape run yourScript.js
你也可以通过命令行参数对抓取进行配置,例如指定抓取的 URL 地址。
flyscrape run yourScript.js --url "http://other.com"
以下是一个抓取 HackerNews 的示例:

项目推介
flyscrape 项目 README 文档写得非常详细,如果你在使用过程遇到问题,很容易找到解决方法或者向社区求助。
以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/philippta/flyscrape
开源项目作者:philippta
开源协议:
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。