
针对中文特殊优化的大语言模型

大家好,又见面了,我是 GitHub 精选君!
背景介绍
在自然语言处理(NLP)的研究和应用中,如何有效地利用大型语言模型进行中文文本处理是一个关键的挑战。这方面的问题主要包括中文词表的扩展,大模型的训练和部署,中文语义理解能力的提升等。
今天要给大家推荐一个 GitHub 开源项目 ymcui/Chinese-LLaMA-Alpaca,该项目在 GitHub 有超过 15.8k Star,用一句话介绍该项目就是:“中文LLaMA&Alpaca大语言模型+本地CPU/GPU训练部署 (Chinese LLaMA & Alpaca LLMs)”。

项目介绍
Chinese-LLaMA-Alpaca 开源了中文 LLaMA 模型和指令精调的 Alpaca 大模型,以进一步促进大模型在中文 NLP 社区的开放研究。项目在原来 LLaMA 模型的基础上进行了中文化的优化,适应了中文语料的处理。同时,通过 Alpaca 模型的指令数据进行精调,显著提高了模型对指令理解和执行的能力。项目提供了预训练脚本、指令精调脚本,用户可以根据需要进一步训练模型。而且,项目支持在配置较低的个人电脑上的 CPU/GPU 进行模型的训练和部署,极大提高了模型使用的便利性。
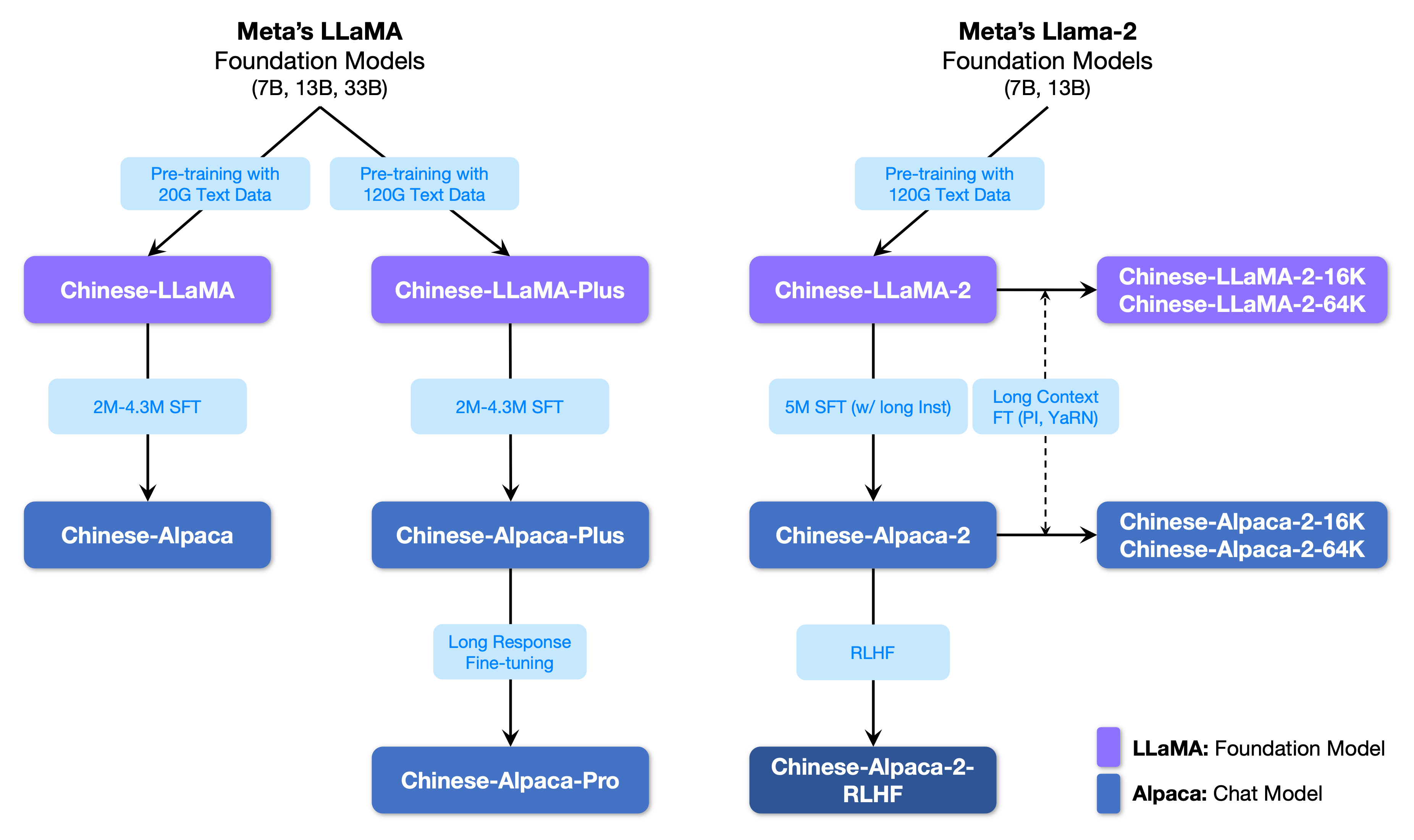
以下是该项目开源的模型与 LLaMA 的关系图:
以下是一个使用示例:
如何使用
可以根据项目给出的教程,先下载 LoRA 模型,然后按照步骤与 LLaMA 模型进行合并,以获得完整的模型权重。项目提供了详细的本地推理与快速部署教程,还有具体的各种使用场景的代码示例,帮助用户快速上手。
以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca
开源项目作者:ymcui
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。