
先进的开源文本转语音功能库

大家好,又见面了,我是 GitHub 精选君!
背景介绍
您是否在寻找一个低延迟、高性能的文本转语音(TTS)工具?是否遇到只能支持有限语言的问题,或者想要自己训练和微调模型?如果这些问题困扰着您,那么我想您会对以下这个项目感兴趣。
TTS 项目在 GitHub 有超过 24.4k Star,用一句话介绍该项目就是:“a deep learning toolkit for Text-to-Speech, battle-tested in research and production”。

项目介绍
TTS 是一个先进的开源文本转语音生成功能库,它具有以下特点:
1、提供 1100 种预训练模型,覆盖各种语言。
2、一键生成新模型或微调现有模型。
3、具备数据集分析和精细化策划功能工具。
以下是 TTS 的性能表现:
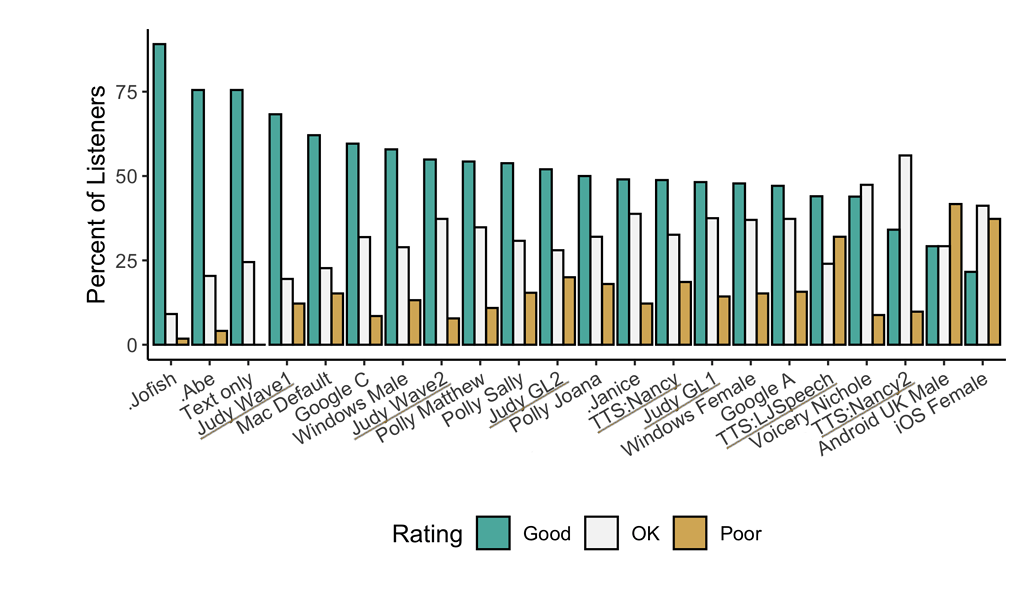
不仅如此,Coqui.ai/TTS 采用了许多先进的深度学习模型,从 Tacotron、Tacotron2、Glow-TTS 到 SpeedySpeech。该项目同时也提供了一系列的声码器模型,包括 MelGAN、Multiband-MelGAN、GAN-TTS、ParallelWaveGAN、WaveGrad 和 WaveRNN。

如何使用
安装和使用 TTS 非常简单。
pip install TTS
# 源码安装
git clone https://github.com/coqui-ai/TTS
pip install -e .[all,dev,notebooks]
在自己的开发环境安装后,只需要设定几个配置文件并运行一段代码,您便可以进行模型的训练和微调。以下是一个简单的文字转语音的代码示例:
# Init TTS with the target model name
tts = TTS(model_name="tts_models/de/thorsten/tacotron2-DDC", progress_bar=False).to(device)
# Run TTS
tts.tts_to_file(text="Ich bin eine Testnachricht.", file_path=OUTPUT_PATH)
# Example voice cloning with YourTTS in English, French and Portuguese
tts = TTS(model_name="tts_models/multilingual/multi-dataset/your_tts", progress_bar=False).to(device)
tts.tts_to_file("This is voice cloning.", speaker_wav="my/cloning/audio.wav", language="en", file_path="output.wav")
tts.tts_to_file("C'est le clonage de la voix.", speaker_wav="my/cloning/audio.wav", language="fr-fr", file_path="output.wav")
tts.tts_to_file("Isso é clonagem de voz.", speaker_wav="my/cloning/audio.wav", language="pt-br", file_path="output.wav")
项目推介
TTS 的开源社区非常活跃且开发进展非常迅速,以下是最近的一些进展:
 以下是该项目 Star 趋势图(代表项目的活跃程度):
以下是该项目 Star 趋势图(代表项目的活跃程度):
更多项目详情请查看如下链接。
开源项目地址:https://github.com/coqui-ai/TTS
开源项目作者:coqui-ai
以下是参与项目建设的所有成员:
关注我们,一起探索有意思的开源项目。
更多精彩请扫码关注如下公众号。